
The value attribution problem and pricing
How can we attribute value between multiple solutions

TL;DR (Too Long; Didn’t Read)
The value attribution problem may be the most important unsolved challenge in AI-era pricing. Here’s why it matters and what we’re doing about it.
The ‘we’ being Steven Forth from Pattern Mind Studio and valueIQ, Michael Mansard from Zuora and Edward Wong from GTM Pricing.
Outcome-based pricing has a fatal flaw. Three conditions must be met for it to work — agreed outcomes, fair value attribution, and predictability. Most solutions fail on condition two. That’s the problem this research is trying to crack
“Who created this value?” has no rigorous answer yet. When a price change, a sales campaign, an AI agent, and market conditions all contribute to an outcome, there is currently no principled way to allocate credit — or price — between them
Static value models are already obsolete. Tom Nagle’s EVE framework was built for a world of point-in-time snapshots. In a world of orchestrated AI agents interacting dynamically, you need value attribution over time — not just a moment
Solving this unlocks far more than outcome-based pricing. Value attribution networks will become the architectural blueprint for agent orchestration — determining which agents act, in what sequence, and who gets paid for what
The solution requires three disciplines that have never been combined. Cooperative game theory (Shapley value, Myerson value) tells you how to allocate fairly. Judea Pearl’s causal models tell you what actually caused the outcome. Temporal Difference Learning tells you how value evolves and how predictions should be corrected
This is active, collaborative research — not theory. The team is building formal problem definitions, generating concept blends and synthetic data sets, with working sessions scheduled in Paris and Vancouver
A value attribution engine could also be a value prediction engine — and prediction is the third missing condition for outcome-based pricing to work. Solve attribution, and you may solve prediction at the same time
The agent economy will not wait. Vendors and customers are already signing outcome-based contracts where neither side can answer “who created this value?” Follow this research to be ahead of the moment that question becomes unavoidable
Outcome based pricing is a popular theme these days, with many analysts saying that it is the future for AI applications and AI enabled pricing. Maybe.
There are three conditions that need to be met for outcome based pricing to be a viable solution.
All parties can agree on the outcome(s)
The value created can be fairly attributed to the different parties
The outcome is at least to some degree predictable
These three conditions are satisfied by very few solutions (lead generation and customer resolution being two common exceptions). If these conditions are not satisfied outcome based pricing will flail, people will get into arguments, and you will in general have been better off with some other pricing model.
In this post the focus is value attribution, which I feel is the most difficult thing to solve.
I am working with Michael Mansard of Zuora and Edward Wong of GTM Pricing to see if we can develop and test a solution to this problem.
What is value attribution?
The ‘value attribution problem’ is the question of how to attribute value (and then allocate price) when there are multiple actors contributing to the outcome.
Example, how much did the price increase, change in packaging, improved pricing page design, sales campaign, market conditions … contribute to the change in revenue.
There are multiple causes in play here. Some are new designs and systems perhaps provided by an external vendor (who wants to be paid part of the value they contribute to the outcome). Others are internal changes to processes, people, incentives. These both have costs and need to be considered in making a decision. Others are external, market conditions, that are not under anyones control (sometimes you just get lucky).
Most things that matter have multiple, interacting causes. We now have the tools (causal models, causal machine learning) to tease out and test these relationships. Being able to do so will help us make better decisions and resource allocations and enable new pricing models including outcome based pricing.
Why is value attribution a problem?
Value attribution is a gate for outcome based pricing, but it is much more than that.
Solving value attribution means understanding the causal network of how different solutions and actions interact with the environment to create outcomes, desired or otherwise. Understanding these relationships helps one decide what actions to take and the order of the actions.
Using the ‘improved revenue’ example, understanding the dependencies between offer, price, value, sales training, sales tools, sales incentives and how they interact will inform decisions on what to do and in what order.
These causal networks could also play an important role in agent orchestration, which is as much about what agents to connect and in which order as it is about choosing agents. Agent orchestration will have a time dimension.
An adaptive value attribution solution will even help with value optimization, designing interventions that maximize the possible value.
What happens if we solve the value attribution problem?
Solving value attribution will take value modelling the next step. The current generation of value models, the ones based on Tom Nagle’s Economic Value Estimation (EVE) approach, are generally snapshots of value at a point in time or value aggregations. They don’t really help us to understand value over time (see Pricing and value over time) or how the different value drivers interact. In a world of quasi interacting agents this is not good enough.
Value attribution networks (or maps, or graphs or whatever we call them) will become key context for agent orchestration. They will be used to optimize the sequence in which agents act.
From value it is a short step to pricing. Unlocking value attribution will enable new approaches to pricing that are needed for the agent economy. Outcome based pricing is just one part of this. The other dimensions are emergent, but will include collaborative pricing, pricing that better aligns with value over time, pricing negotiated between agents and many other core activities in the agent economy.
What solutions are we exploring
If this was an easy problem it would already be solved. Value attribution is a hard problem because it cannot be solved from any one point of view. It will require some form of concept blending (as do many innovations, see Some innovation patterns from concept blending).
We are beginning by exploring concept blends of Game Theory, Causal Modelling and Temporal Difference Learning. We will proceed pairwise and then combine pairs in different ways to get a full exploration of these blends and their possible applications to value attribution.
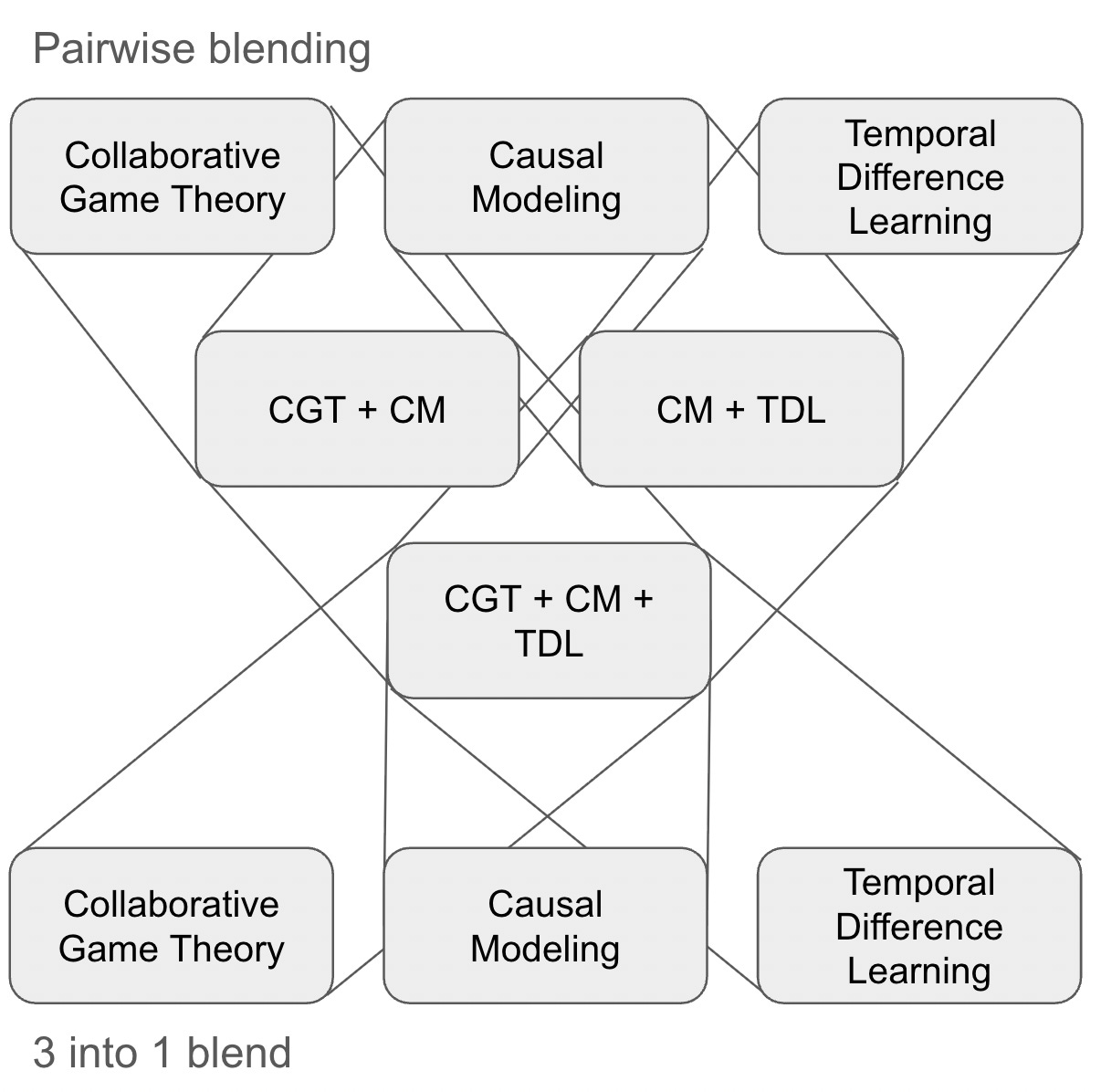
(In fact, for the pairwise blending, we will generate and compare all three concept blend sequences: CGT + CM + TDL; CM + TDL + CGT; TDL + CGT + CM. It will be interesting to see what if any are the differences between each sequence.)
From Game Theory
The obvious place to start is with game theory and specifically with cooperative game theory (Shapley value, core, nucleolus, Myerson value).
Cooperative game theory studies how groups of players (coalitions) can work together to achieve outcomes better than they could alone, and — critically — how to fairly or stably distribute the resulting gains. Unlike non-cooperative game theory, which focuses on individual strategic choices, cooperative game theory takes the coalition as the unit of analysis and asks: what should each player receive?
The field is formalized through a characteristic function v(S), which assigns a value to every possible coalition S, representing what that coalition can guarantee for itself. Solution concepts then prescribe how the grand coalition’s total value should be allocated.
Core
The core is the set of all payoff allocations that are both feasible and stable — meaning no sub-coalition can do better by breaking away and acting on its own. An allocation is in the core if every coalition receives at least as much as it could generate independently. The core prioritizes preventing defection, but it can be empty in some games (e.g., majority voting games), meaning no universally stable allocation exists.
Shapley Value
Introduced by Lloyd Shapley in 1951, the Shapley value assigns each player their average marginal contribution across all possible orderings in which players might join the grand coalition. It is the unique solution satisfying four axioms — efficiency (full distribution), symmetry (equal treatment of equal contributors), additivity, and the dummy player property (zero contribution = zero payoff). The Shapley value is the dominant fairness-oriented solution concept, widely used in profit sharing, cost allocation, and ML feature attribution, though it does not guarantee stability (it may fall outside the core).
Any solution to the attribution problem must satisfy Shapley’s four axioms.
Nucleolus
The nucleolus, introduced by Schmeidler (1969), minimizes coalitional dissatisfaction. It does this by lexicographically minimizing the maximum excess — the gap between what a coalition could earn on its own and what it actually receives under an allocation. The nucleolus always exists, is unique, and whenever the core is non-empty, the nucleolus lies within it. It is the “least worst” allocation, prioritizing the most aggrieved coalition at each step.
Myerson Value
The Myerson value extends the Shapley value to games played on a communication graph, where not all coalitions are feasible — only players who are connected in the network can cooperate. Each player’s payoff is computed as their Shapley value within the restricted game defined by the graph’s connected components. It elegantly captures how network structure (who can communicate with whom) shapes fair allocation, making it especially relevant for supply chains, joint ventures, and platform ecosystems where bilateral relationships constrain coalition formation.
The notion of a communication graph is intriguing here, espacially when applied to agents and MCP (the Model Context Protocol).
From Causal Modelling
Judea Pearl is a key figure in modern computing and won the Turing award in 2011. In the words of the award committee,
"He pioneered developments in probabilistic and causal reasoning and their application to a broad range of problems and challenges. He created a computational foundation for processing information under uncertainty, a core problem faced by intelligent systems. He also developed graphical methods and symbolic calculus that enable machines to reason about actions and observations, and to assess cause?effect relationships from empirical findings. His work serves as the standard method for handling uncertainty in computer systems, with applications ranging from medical diagnosis, homeland security and genetic counseling to natural language understanding and mapping gene expression data. His influence extends beyond artificial intelligence and even computer science, to human reasoning and the philosophy of science."
The applications to the attribution problem seem clear, as what we are tying to understand is the causal relationship between actions under uncertainty.
The framework rests on three interlocking tools:
Directed Acyclic Graphs (DAGs): Nodes represent variables; directed edges (arrows) represent direct causal influences. The graph is acyclic, meaning no variable can cause itself through a chain of effects.
Structural Causal Models (SCMs): Each variable XjXj is defined by a structural equation Xj=fj(PAj,εj)Xj=fj(PAj,εj), where PAjPAj are its direct causes (”parents” in the graph) and εjεj is an exogenous noise term.
Do-calculus and the do-operator: The notation do(X=x)do(X=x) mathematically represents an intervention — forcing a variable to a value — as distinct from merely observing it. This is the key move that separates causal reasoning from correlation.
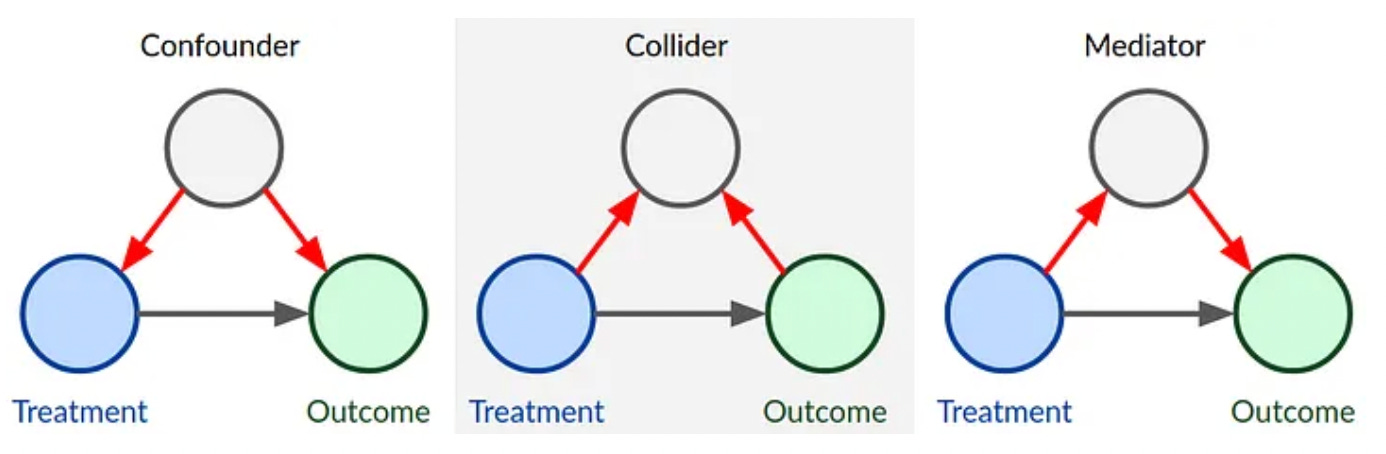
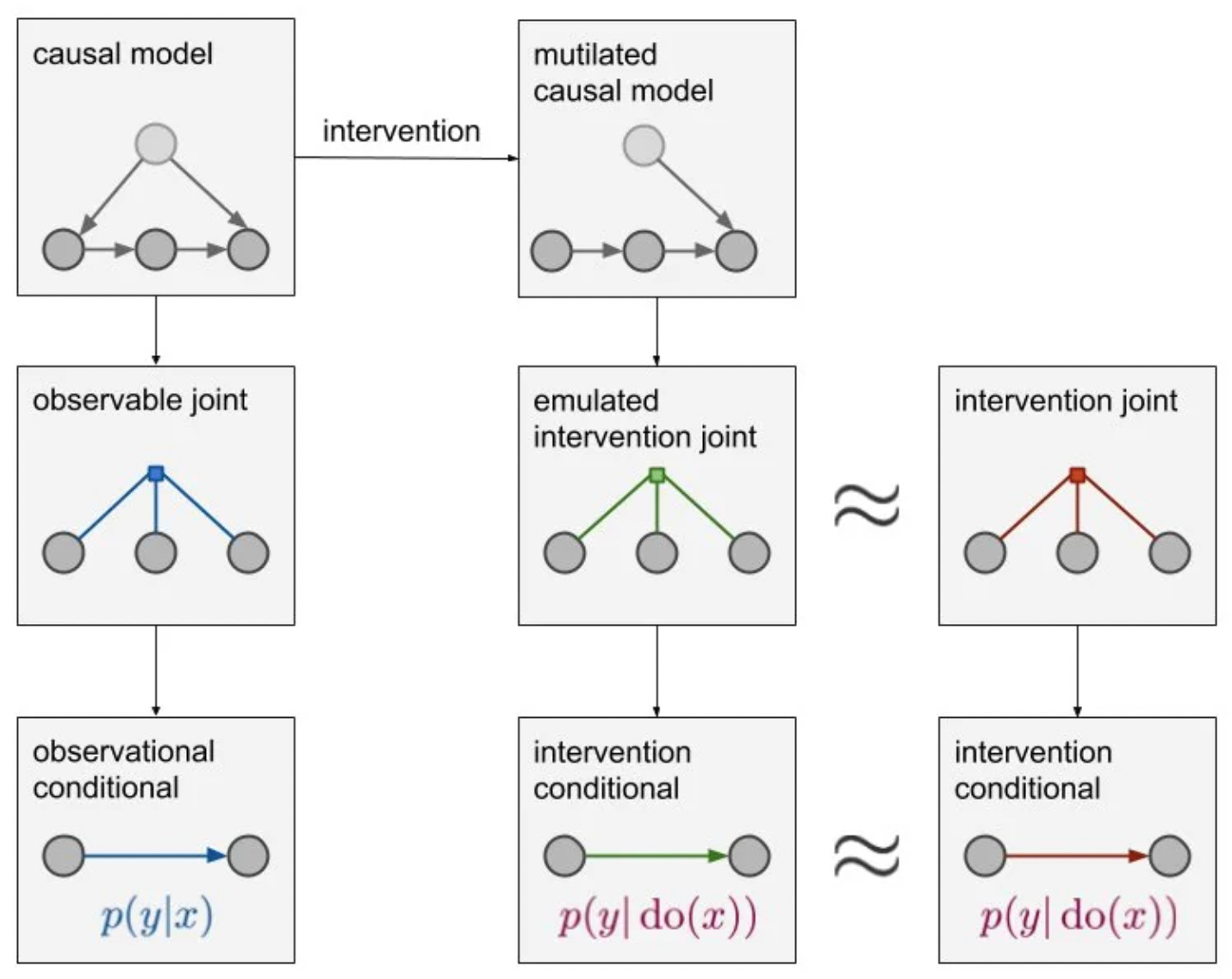
(The basic types of causal graphs. We are looking at using CausalWizard to help us build causal models.)
D-Separation and Identification
A key graphical tool is d-separation, which lets you read conditional independencies directly off the DAG without any algebra. This is what allows researchers to determine whether a causal effect is identifiable from observational data — and if so, which variables need to be measured or controlled for. The fundamental result is that in a Markovian (acyclic, independent errors) model, all causal effects are identifiable, and only the direct parents of a variable need to be measured to estimate its causal effect.
If we can get to a point where all causal effects are identifiable we will have made good progress on our problem.
From Temporal Difference Learning
Temporal Difference (TD) learning is a reinforcement learning method that updates value estimates incrementally by bootstrapping — comparing predictions made at successive time steps rather than waiting for a full episode to complete.
The Core TD Mechanism
At each time step, the agent observes a reward rr and transitions to a new state. The TD error δδ captures the gap between the current value estimate and a better estimate based on the next state:
δ(t)=r(t)+γV(st+1)−V(st)δ(t)=r(t)+γV(st+1)−V(st)
where γγ is a discount factor. A positive δδ means outcomes were better than expected; a negative δδ means they were worse. This signal drives all learning updates.
The Policy Agent (Actor)
The actor is responsible for selecting actions — it embodies the policy πθπθ, mapping states to actions. Its goal is to improve behavior over time by adjusting policy parameters in the direction that increases expected cumulative reward. Crucially, the actor doesn’t evaluate its own choices; it relies entirely on feedback from the critic to know whether its decisions were good.
The Critic
The critic learns a value function — typically V(s)V(s) or Q(s,a)Q(s,a) — that estimates expected future reward from any given state. After each action, the critic computes the TD error δδ and uses it to update its own value estimates. This scalar TD error is then fed back to the actor as the learning signal. The critic doesn’t select actions; it purely evaluates the consequences of the actor’s choices.
How They Work Together
The two components form a feedback loop:
Actor selects an action based on current policy
Environment returns a reward and new state
Critic computes the TD error between predicted and observed value
TD error updates both the critic’s value function and the actor’s policy parameters
This division of labor is efficient: the critic reduces the variance inherent in pure policy-gradient methods, while the actor handles the complexity of action selection in large or continuous action spaces without requiring the critic to enumerate all possible actions.
I suspect our solution will need to have a policy agent and a critic, with the policy agent making predictions about future value and the critic checking those predictions and providing feedback to the prediction agent.
The prediction agent will be modelling causality and allocating contributions to the different actors and their actions.
In this way, a value attribution solution could also be a value prediction solution. And prediction is one of the other key requirements for outcome based pricing.
Where we are
We are at the beginning of this journey and welcome your comments and suggestions. Please put them in the comments section below or reach out to any of us on LinkedIn.
The next steps are to
Prepare a more formal problem definition that can be used to test if we have made progress in solving the problem
Prepare the deep context documents we will use with our AIs for the concept blends
Prepare a set of synthetic data that can be used for training and testing (for more on synthetic data see Synthetic data in pricing)
We will be having a working session in Paris in late April and are happy to meet with people to share ideas at that time. There will be another working session in Vancouver later in the year.
Conclusion
Every pricing model you have built, every outcome-based contract you have signed, every value conversation you have had with a customer — all of them rest on an assumption that has never been rigorously solved: that you can fairly attribute value to the actions that created it.
In a world of seat licenses and static software, that assumption was forgivable. In a world of orchestrated AI agents, collaborative ecosystems, and outcome-based pricing, it is not. The agent economy will not wait for pricing theory to catch up. Vendors and customers are already negotiating contracts where neither party can precisely answer the question: who created this value, and how much?
What makes this problem genuinely exciting — and genuinely hard — is that solving it requires you to stand at the intersection of three disciplines that have never been properly introduced to each other. Cooperative game theory tells you how to allocate fairly. Pearl’s causal models tell you what actually caused the outcome. Temporal difference learning tells you how value evolves and how predictions should be corrected over time. No single framework is sufficient. The breakthrough will come from their synthesis.
That synthesis is what this research is chasing.
The working sessions in Paris and Vancouver are not academic exercises. They are the first attempts to build practical tooling — value attribution networks, actor-critic architectures for pricing, causal graphs as agent orchestration context — that will reshape how the next generation of B2B SaaS and AI companies price their solutions.
If you are building outcome-based pricing today, this work will either validate your approach or expose its hidden assumptions. If you are designing AI agent products, the causal graph of your value creation is not just a pricing instrument — it is the architectural blueprint for how your agents should be sequenced and optimized.
Follow this research. Comment. Challenge the framework. The formal problem definition, the concept blends, the synthetic data experiments — all of it will be published here as the work develops. The value attribution problem is one of the most consequential unsolved problems sitting at the intersection of AI economics and pricing strategy.
Some references (not complete)
Fauconnier & Turner (1998) — "Conceptual Integration Networks." Cognitive Science, 22(2)).
Fauconnier & Turner (2002) — The Way We Think: Conceptual Blending and the Mind's Hidden Complexities. Basic Books.
Forth, Steven (2022) “Some Innovation Patterns from Concept Blending” on LinkedIn.
Forth, Steven (2026) “Synthetic Data in Pricing” on Pricing Innovation.
Nagle, Thomas T., Georg Mueller, Everet Gruyaert (2023) The Strategy and Tactics of Pricing: A Guide to Growing More Profitably, 7th Edition. Routledge.
Pearl, Judea (2009) Causality, 2nd Edition. Cambridge University Press.
Pearl, Judea with Dana Mackenzie (2018) The Book of Why. Basic Books.
Schmeidler, D. (1969) The Nucleolus of a Characteristic Function Game. SIAM Journal of Applied Mathematics, 17, 1163-1170.
Shapley, Lloyd S. (1951). “Notes on the n-Person Game -- II: The Value of an n-Person Game”. RAND Corporation.
Sutton, Richard (1988). “Learning to Predict by the Method of Temporal Differences.” Machine Learning 3(1):9-44
Watkins & Dayan (1992). "Q-Learning" Machine Learning, 8, 279-292.
Two thoughts. 1) Correlation is not causation. 2) Success has a thousand fathers and failure is an orphan.