
Rubrics for transparent value and pricing models
The Value Project

TL;DR
Pricing in B2B SaaS and business AI is now fundamentally about designing systems, not updating price lists.
The old model of “set a price once a year and call it done” is breaking under usage-based, AI-augmented, and multi-sided product realities.
Pricing decisions are increasingly entangled with product design, data infrastructure, consent/identity, and organizational governance; treating pricing as a siloed function is a liability.
Value is shifting from discrete features to composable capabilities, workflows, and outcomes; pricing needs to map to value paths, not modules or seats.
AI intensifies value asymmetry: small differences in model performance, data quality, or workflow fit can drive outsized business impact, and pricing must be tuned to capture that non-linearity.
Standard “good / better / best” packaging often obscures value in AI products; you need offers built around specific jobs-to-be-done, risk profiles, and learning curves.
Usage is noisy and hard to predict, so “pure” usage-based pricing can destabilize both buyer and seller; hybrid models that bound risk (floors, ceilings, committed use, bands) work better.
Many AI offers are underpriced relative to the value they create because teams anchor on cost-plus or competitor benchmarks instead of quantified value models.
You should explicitly model causal links between product usage, behavior change, and business outcomes; this is the bridge between value stories and monetization.
Outcome-based pricing only works when you can credibly measure the outcome and allocate it fairly across all contributing factors (product, data, change management, macro conditions).
Metrics selection is now a pricing design decision: choose reference metrics that are observable, attributable, and aligned with how your customer actually runs the business.
Your data model, event taxonomy, and analytics stack are now part of your pricing architecture; if you cannot measure value, you cannot charge for it.
Incentive alignment must be designed: your pricing should encourage the behaviors that drive long-term value (adoption depth, experimentation, high-quality data), not just short-term revenue spikes.
Governance matters: pricing needs a cross-functional council spanning product, finance, sales, data, and legal to manage experiments, guardrails, and exceptions.
You should treat pricing like an evolving algorithm: define hypotheses, run controlled experiments, and continuously update based on signal, not anecdotes.
AI makes it possible to personalize pricing and packaging, but you need clear policies to avoid hidden discrimination, channel conflict, and regulatory risk.
Transparency is now strategic: customers expect to see how usage, outcomes, and price relate; opaque “black box” AI pricing will erode trust and slow adoption.
For enterprise AI, value realization is constrained by change management more than by model performance; pricing should support onboarding, experimentation, and delayed value capture.
You should invest in “value operations” capabilities: playbooks, calculators, ROI narratives, and in-product prompts that help customers see and quantify value as they use the product.
Discounting needs to be recast as structured risk-sharing (e.g., ramp deals, outcome guarantees, value-based milestones) rather than ad hoc negotiation.
Partner ecosystems (data, services, platforms) complicate who gets paid for what; you will need explicit revenue-sharing and co-pricing frameworks for AI-native alliances.
Regulatory and ethical constraints (privacy, bias, explainability) will shape what you can charge for and how; pricing leaders must track policy as a design constraint, not an afterthought.
The real moat in pricing innovation is organizational learning: teams that can rapidly sense, test, and adapt pricing patterns will out-iterate competitors locked into static models.
Executive Action Items
Appoint an owner for “pricing system design” with a mandate across product, data, and GTM, not just finance.
Build a simple but explicit value model for your top 2–3 AI use cases and use it to test whether your current pricing actually tracks value.
Define a 12–18 month roadmap for evolving from static price lists to a governed, experiment-driven pricing system.
Upgrade your data and event model so you can measure the core value metrics your pricing depends on.
Introduce one new pricing experiment per quarter (e.g., new metric, new bundling, new commitment structure) and review results in a standing pricing council.
Link to Rubric Evaluating Online Representations of Pricing Models
Provided under a CC BY-SA 4.0 License
Link to Rubric for Evaluating Online Representations of EVE-Style Value Models
Provided under a CC BY-SA 4.0 License
Use these two rubrics (i) to evaluate your online representations of value models and pricing models for AI agents and (ii) to generate these descriptions.
The rubrics have also been designed for use in Reinforcement Learning with Verifiable Results (RLVR) training where the rubric is used to provide feedback in the training process.
Use with the schemas provided by The Value Project.
Do the schemas provided by The Value Project make a difference?
The Value Project has an explicit goal, to make EVE-style value models and pricing models more transparent and computable. These models, when shared on a website, should make it easier for AI answer agents and AI buying agents to understand and answer questions about value and pricing.
I introduced the project in Portable and computable value and pricing models. You may want to read this before proceeding with the rest of this post.
Here I want to test the pricing model schema. I do this by generating a rubric for online, machine readable pricing models (there is also a rubric for machine readable EVE stye pricing models shared at the end of this post). I use a rubric as rubrics are heavily used in machine learning (there are several rubrics embedded in the different valueIQ agents) and rubrics are being used to extend the RLVR (Reinforcement Learning with Verifiable Results) approach to fields where the results are not as black and white as math or code (the code compiles or it does not, it passes unit tests or it does not) such as value and pricing, where models can be more or less right.
After generating the rubric I used it to compare two pricing models, one in the schema specified by The Value Project and one that looks nice and technical but was done independently. I want to see how each scores on the rubric. I plan to run the rubric on every formal pricing (and value) model that I can find!
Buffer.com ‘Machine readable pricing for AI agents’ https://buffer.com/pricing.md
valueIQ ‘Machine readable pricing model for AI agents’ https://valueiq.ai/pricing-model.md
Here are the results reported by the rubric
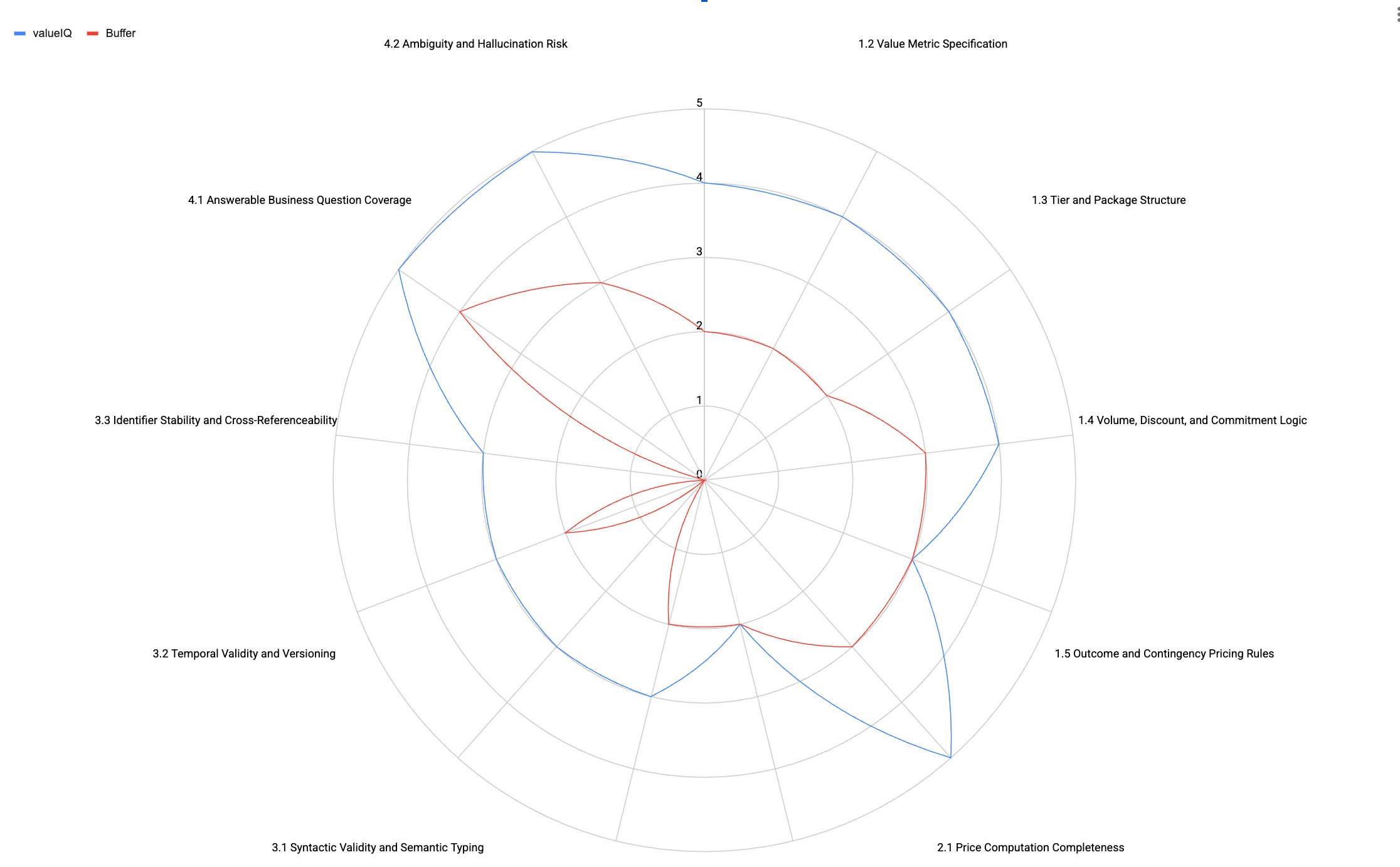
Comparison of Buffer.com and valueIQ.ai
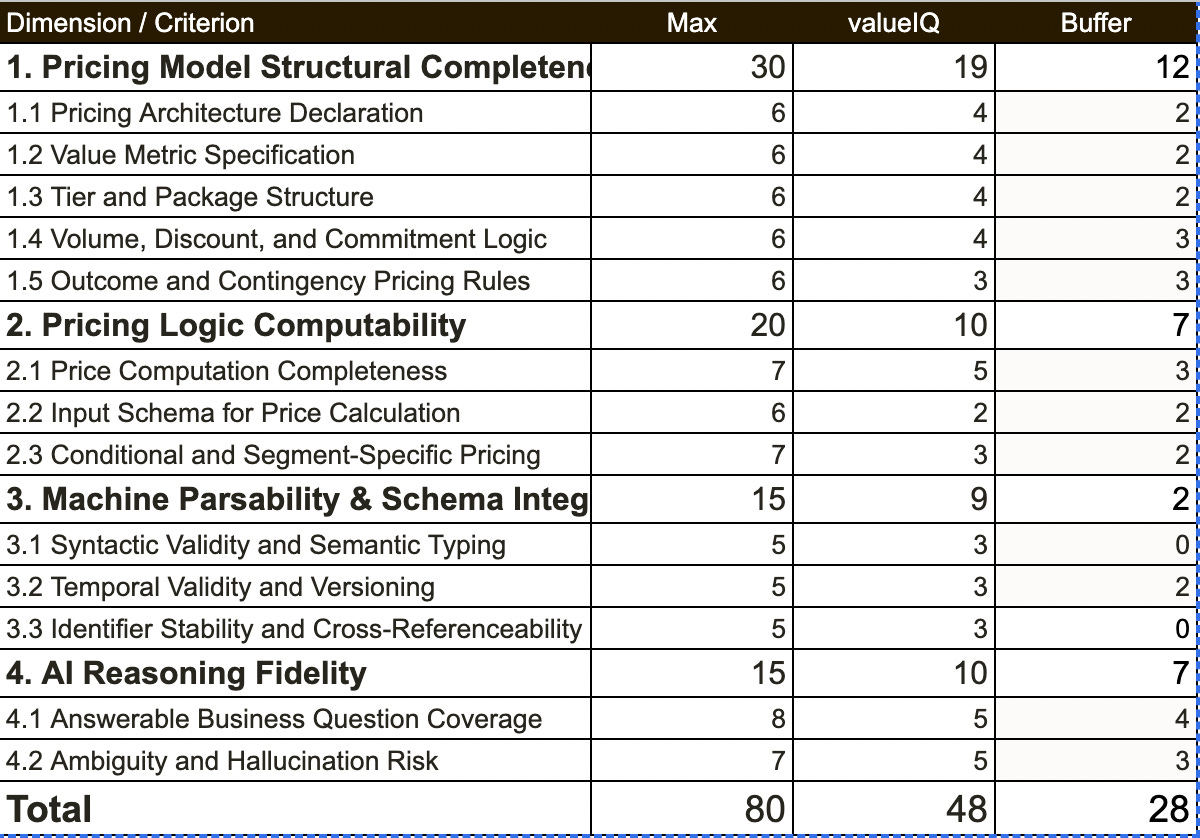
Both representations have room for improvement but the one in The Value Project format clearly outperforms the less structured representation. Some further research is needed to see if the shortcomings are with the valueIQ pricing model per se or with the technical format provided by The Value Project.
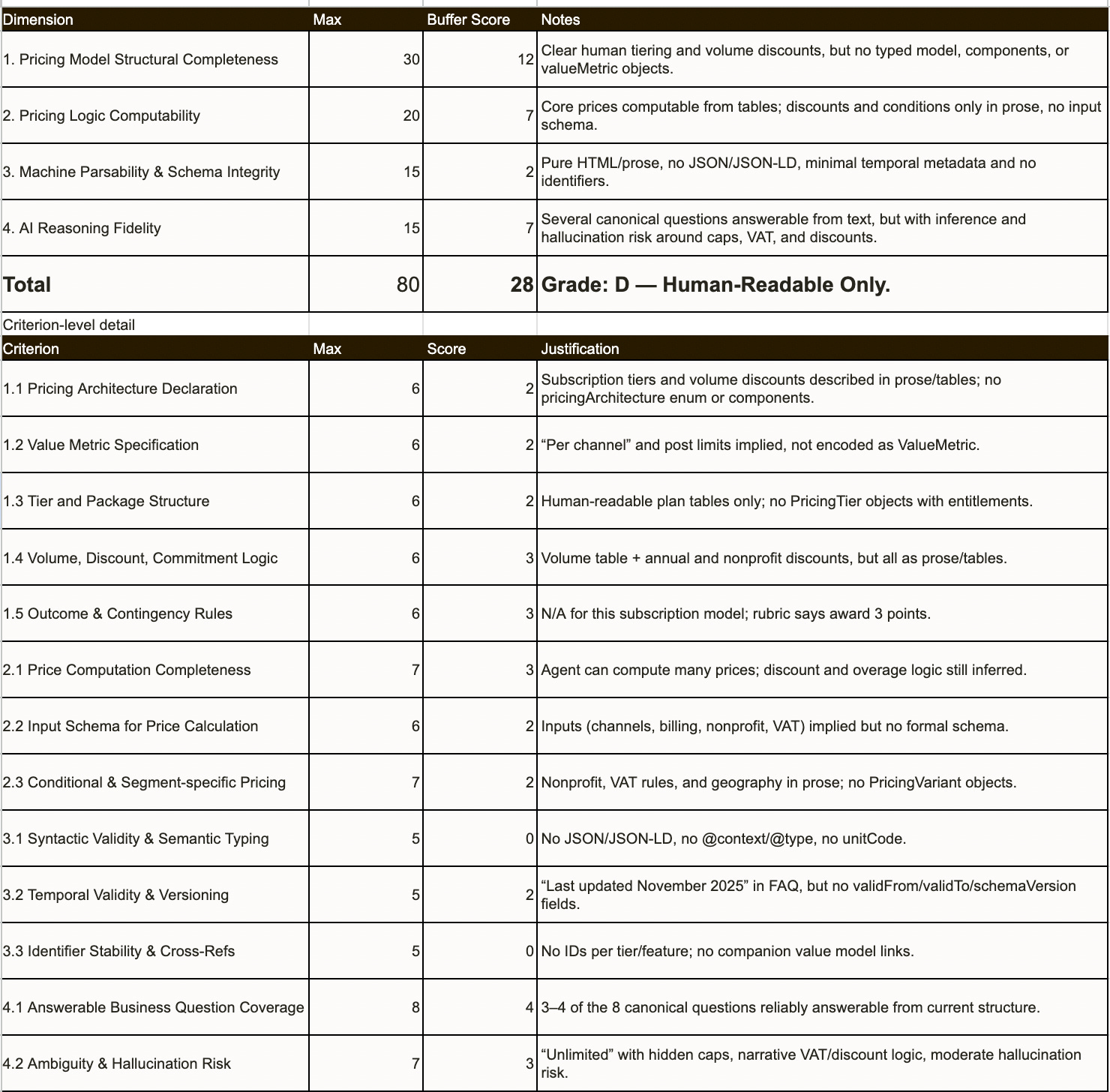
Assessment of Buffer.com pricing model representation for AI
Assessment of valueIQ.ai pricing model representation for AI
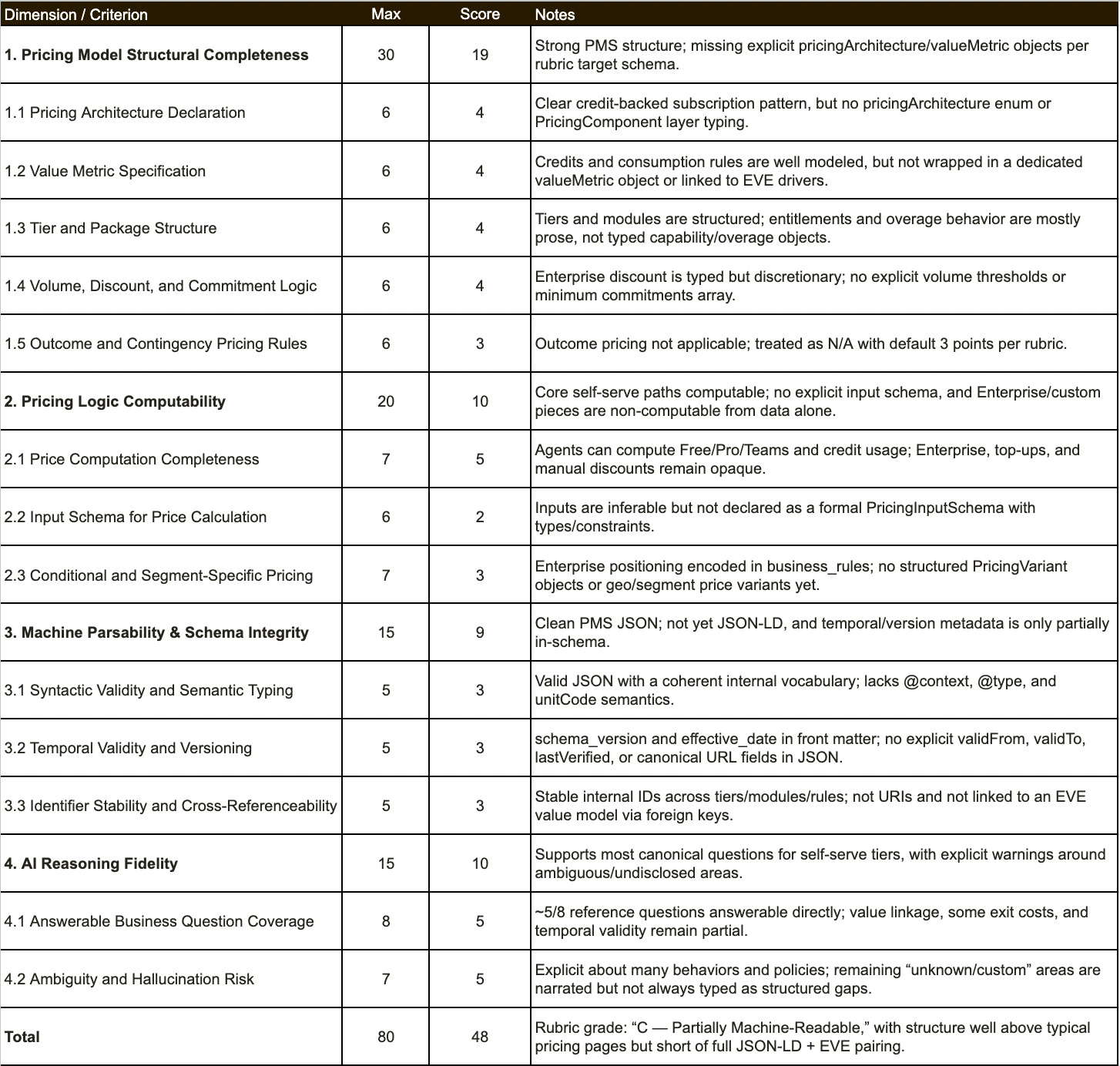
This result will be used by The Value Project to improve the schema and by valueIQ to improve its pricing.
Note that only the pricing model was evaluated so the comments about lack of linkage to the value model are not really fair. I plan to redo this providing the value model and the pricing model to an assessment prompt that has the two rubrics as context.
Rubric for pricing models
Rubric Evaluating Online Representations of Pricing Models
May 26, 2026
Purpose and Scope
This rubric evaluates how well a published pricing model is structured for consumption by AI answer engines and AI agents. It scores a representation against four quality dimensions and generates feedback signals for improving the technical standard used to represent pricing models in JSON-LD or equivalent structured formats.
A well-formed pricing model must allow an AI to answer: What does this solution cost for a specific configuration, customer profile, and usage level — and why is it priced that way?
Total score: 80 points. Each criterion includes a feedback signal that maps directly to a recommended change in the technical standard.
Dimension 1: Pricing Model Structural Completeness (30 points)
Criterion 1.1 — Pricing Architecture Declaration (6 pts)
Evaluates whether the model’s fundamental pricing structure is explicitly typed and decomposed into layers.
Score
Descriptor
6
Pricing model type declared from a controlled vocabulary (enum: subscription, consumptionBased, seatBased, capabilityBased, outcomeBased, hybrid); architecture layers (base fee, variable component, minimum commitment, overage) declared as separate typed PricingComponent objects; relationship between layers explicitly modeled
5
Model type declared from vocabulary; layers separated into typed objects; relationship between layers absent
4
Model type declared from vocabulary; layers present but not typed as separate objects
3
Model type declared as a string label; no structural decomposition
2
Pricing described in prose only
1
Pricing referenced but not described
0
Absent
Feedback signal: Standard requires a pricingArchitecture enum field drawn from a maintained vocabulary, plus a pricingComponents[] array for each billable layer.
Criterion 1.2 — Value Metric Specification (6 pts)
The value metric — the unit that determines what the customer pays — is the most AI-critical pricing field and must be linked to economic value.
Score
Descriptor
6
Value metric declared as a typed ValueMetric object with: name, unit, measurementMethod, meteringGranularity (enum: perEvent, perPeriod, cumulative, peak), and linkedValueDriverIds[] referencing the corresponding EVE value drivers
5
Value metric typed with unit, measurement method, and metering granularity; linkedValueDriverIds absent
4
Value metric typed with unit and measurement method; granularity and linkage absent
3
Value metric named and typed but not formally measured
2
Value metric implied by tier labels (e.g., “per user”)
1
Value metric embedded in a prose pricing description
0
Absent
Feedback signal: Standard requires a valueMetric object with a mandatory linkedValueDriverIds[] foreign key to establish alignment between the pricing mechanism and the value model.
Criterion 1.3 — Tier and Package Structure (6 pts)
Score
Descriptor
6
All tiers declared as typed PricingTier objects with: tierName, price, currency, billingPeriod (enum: monthly, annual, event, outcome), includedEntitlements[] as typed capability objects, overageRules, and upgradeDowngradeLogic
5
Tiers typed with price, currency, billing period, and entitlements; overage rules or upgrade logic missing
4
Tiers typed with price and billing period; entitlements listed as untyped strings
3
Tiers present; entitlements and overage rules in prose only
2
Tiers described as an HTML or prose table not parseable as structured objects
1
Pricing described as a single price point
0
Absent
Criterion 1.4 — Volume, Discount, and Commitment Logic (6 pts)
Discounts and commitment schedules are among the most frequently misrepresented pricing elements for AI systems.
Score
Descriptor
6
Volume discount schedules declared as arrays of typed DiscountRule objects with {threshold, thresholdUnit, discountType (enum: percentOff, flatRate, newUnitPrice), discountValue}; commitment-based discounts typed separately; minimum commitment and ramp structures declared
5
Discount arrays present with threshold and value; discount type or threshold unit absent on ≤ 2 rules
4
Discount arrays present; discount type absent from most rules
3
Discount schedules present but encoded as prose ranges or narrative tables
2
Discounts mentioned without structure
1
“Contact us for pricing” or similar; no discount information
0
Absent
Criterion 1.5 — Outcome and Contingency Pricing Rules (6 pts)
For outcome-based and hybrid models, contingent pricing logic must be fully typed to be AI-computable.
Score
Descriptor
6
Contingent pricing conditions declared as typed PricingRule objects with: condition (structured predicate), measuredOutcome, outcomeUnit, price, currency, settlementMechanism; baseline and measurement methodology declared
5
Contingent rules typed; baseline or measurement methodology absent
4
Contingent rules typed but condition expressed as prose string
3
Outcome pricing described in structured annotations but not computable
2
Outcome pricing referenced in prose only
1
Not applicable — model type does not support contingent pricing (mark N/A; award 3 pts)
0
Absent for model types where it should be present
Dimension 2: Pricing Logic Computability (20 points)
Criterion 2.1 — Price Computation Completeness (7 pts)
An agent should be able to compute a price quote for a given configuration from the model alone, without calling an external API.
Score
Descriptor
7
Given all required inputs (tier selection, usage quantity, commitment term, applicable segment), the model provides sufficient structured data to compute an exact price; all pricing rules are typed conditionals, not prose; edge cases (free tier limits, overage caps, minimum charges) are typed
5–6
Most price paths computable; 1–2 edge cases in prose
3–4
Core tier prices computable; discount and overage logic requires inference
1–2
Prices readable but not computably derivable
0
Price computation impossible from structured data alone
Criterion 2.2 — Input Schema for Price Calculation (6 pts)
AI agents require a declared input schema to know what information to collect before computing a price.
Score
Descriptor
6
Model declares a PricingInputSchema with all required and optional inputs: type, unit, validation constraints (min, max, allowedValues), prompt text, and defaultValue; a worked example with inputs and computed price output is included
5
Input schema complete; worked example absent
4
Input schema present with types; validation constraints and prompt text missing
3
Required inputs listed as a string array; no types or constraints
2
Inputs implied by tier structure but not formally declared
1
No input schema
0
Absent
Feedback signal: Standard should define a PricingInputSchema object with required and optional inputs, types, constraints, and prompt text — parallel to the InputSchema in the value model standard.
Criterion 2.3 — Conditional and Segment-Specific Pricing (7 pts)
Many B2B pricing models include segment-specific adjustments that must be explicitly typed to avoid AI misapplication.
Score
Descriptor
7
All segment or geography-specific pricing variants declared as typed PricingVariant objects linked to CustomerSegment or geographic scope; conditionals structured as typed predicates, not prose; fallback/default pricing explicitly declared
5–6
Pricing variants typed; fallback pricing absent
3–4
Variants present as separate tier objects without explicit segment linkage
1–2
Variants described in prose; AI must infer applicability
0
No variant pricing; single universal price assumed
Dimension 3: Machine Parsability and Schema Integrity (15 points)
Criterion 3.1 — Syntactic Validity and Semantic Typing (5 pts)
Score
Descriptor
5
JSON syntactically valid; JSON-LD @context and @type declarations present; all types reference a declared namespace; numeric properties carry unitCode (UCUM or UN/CEFACT); currency values use ISO 4217 codes; no encoding errors
4
Valid JSON-LD; unitCode and ISO currency present on ≥ 80% of fields
3
Valid JSON; type labels as strings without namespace; no unitCodes
2
Ad hoc property names; no shared vocabulary; mixed types
1
Structured intent but non-parseable syntax
0
Not structured; HTML table, prose, or image only
Criterion 3.2 — Temporal Validity and Versioning (5 pts)
Stale pricing data is one of the most common causes of AI agent errors in vendor comparisons and procurement workflows.
Score
Descriptor
5
validFrom, validTo, schemaVersion, lastVerified, and supersedes link to prior version all present; model served at a stable canonical URL with application/ld+json content-type; CORS enabled; discoverable via llms.txt or well-known endpoint
4
validFrom, schemaVersion, and canonical URL present; validTo or supersedes absent
3
Publication date present; no validity window or schema version
2
Date in page metadata only; not in model schema
1
No temporal metadata
0
Absent
Feedback signal: Standard must require validFrom, schemaVersion, and canonicalUrl as mandatory fields. validTo, lastVerified, and supersedes strongly recommended.
Criterion 3.3 — Identifier Stability and Cross-Referenceability (5 pts)
Score
Descriptor
5
All entities (tiers, discount rules, pricing components, variants) carry stable @id URIs; valueMetric links to linkedValueDriverIds in the companion EVE model; model includes a provenance block with author, organization, and validation date
4
@id on all named entities; companion model linkage or provenance block partially present
3
Internal ID strings (e.g., “id”: “tier-001”) without namespace; no companion model linkage
2
No entity IDs; objects referenced positionally
1
No cross-referencing mechanism
0
Single flat object; no internal structure
Dimension 4: AI Reasoning Fidelity (15 points)
Criterion 4.1 — Answerable Business Question Coverage (8 pts)
Tests whether the representation supports the canonical pricing question set an AI agent is expected to answer without hallucination or inference errors.
Reference question set:
What is the price for [tier/configuration] billed [monthly/annually]?
How does price scale with [usage metric]?
What is the total cost of ownership over [12/36 months] for [customer profile]?
What discounts are available and under what conditions?
What are the switching or exit costs?
How does the price relate to the economic value delivered?
Are there segment-specific or geography-specific pricing variants?
Is this pricing current, and when was it last updated?
Score
Descriptor
8
All 8 questions answerable from structured data without AI inference beyond declared values
6–7
6–7 questions answerable
4–5
4–5 questions answerable
2–3
2–3 questions answerable
1
1 question answerable
0
None answerable from structured data
Feedback signal: Score profile across the 8 questions identifies exactly which structural elements are missing from the standard.
Criterion 4.2 — Ambiguity and Hallucination Risk (7 pts)
Evaluates how well the representation eliminates conditions that force AI systems to guess or fabricate pricing values.
Score
Descriptor
7
No ambiguous property names; all numeric values carry units; currency explicitly declared in ISO 4217; enumerations use closed controlled vocabularies; all conditional logic expressed as typed predicate objects, not prose; “contact us” pricing gaps are declared, not silently omitted
5–6
Units and currency present; ≤ 2 ambiguous property names or untyped conditionals
3–4
Some values undeclared in units; conditional pricing in prose
1–2
Frequent ambiguity; AI must make assumptions to compute prices
0
Representation designed for human readers only; AI hallucination risk is high
Scoring Summary
Dimension
Max
Score
1. Pricing Model Structural Completeness
30/30
2. Pricing Logic Computability
20/20
3. Machine Parsability and Schema Integrity
15/15
4. AI Reasoning Fidelity
15/15
Total
80/80
Grade Thresholds
Grade
Score
Interpretation
A — Production-Ready
72–80
AI agents can compute price quotes and answer all canonical pricing questions reliably. Reference-quality implementation.
B — Answer Engine Ready
60–71
AI answer engines can address most pricing questions. Discount logic or input schema incomplete.
C — Partially Machine-Readable
44–59
Core pricing intent communicated; discount and conditional logic ambiguities create hallucination risk.
D — Human-Readable Only
28–43
Useful as a training source; not reliable for real-time agent or answer engine use.
F — Non-Compliant
0–27
Does not meet minimum structural requirements for AI consumption.
Minimum Viable Pricing Model (MVPM) Checklist
A representation must include all of the following to achieve a passing score (≥ 44):
@type: PricingModel with @context namespace declaration
pricingArchitecture enum field from the controlled vocabulary
valueMetric object with name and unit
At least one PricingTier object with price, currency, billingPeriod
includedEntitlements[] on each tier (may be empty array for usage-only models)
validFrom timestamp and schemaVersion string
canonicalUrl for the published model
Currency declared in ISO 4217
Rubric Evaluating Online Representations of Pricing Models
May 26, 2026
Purpose and Scope
This rubric evaluates how well a published pricing model is structured for consumption by AI answer engines and AI agents. It scores a representation against four quality dimensions and generates feedback signals for improving the technical standard used to represent pricing models in JSON-LD or equivalent structured formats.
A well-formed pricing model must allow an AI to answer: What does this solution cost for a specific configuration, customer profile, and usage level — and why is it priced that way?
Total score: 80 points. Each criterion includes a feedback signal that maps directly to a recommended change in the technical standard.
Dimension 1: Pricing Model Structural Completeness (30 points)
Criterion 1.1 — Pricing Architecture Declaration (6 pts)
Evaluates whether the model’s fundamental pricing structure is explicitly typed and decomposed into layers.
Score
Descriptor
6
Pricing model type declared from a controlled vocabulary (enum: subscription, consumptionBased, seatBased, capabilityBased, outcomeBased, hybrid); architecture layers (base fee, variable component, minimum commitment, overage) declared as separate typed PricingComponent objects; relationship between layers explicitly modeled
5
Model type declared from vocabulary; layers separated into typed objects; relationship between layers absent
4
Model type declared from vocabulary; layers present but not typed as separate objects
3
Model type declared as a string label; no structural decomposition
2
Pricing described in prose only
1
Pricing referenced but not described
0
Absent
Feedback signal: Standard requires a pricingArchitecture enum field drawn from a maintained vocabulary, plus a pricingComponents[] array for each billable layer.
Criterion 1.2 — Value Metric Specification (6 pts)
The value metric — the unit that determines what the customer pays — is the most AI-critical pricing field and must be linked to economic value.
Score
Descriptor
6
Value metric declared as a typed ValueMetric object with: name, unit, measurementMethod, meteringGranularity (enum: perEvent, perPeriod, cumulative, peak), and linkedValueDriverIds[] referencing the corresponding EVE value drivers
5
Value metric typed with unit, measurement method, and metering granularity; linkedValueDriverIds absent
4
Value metric typed with unit and measurement method; granularity and linkage absent
3
Value metric named and typed but not formally measured
2
Value metric implied by tier labels (e.g., “per user”)
1
Value metric embedded in a prose pricing description
0
Absent
Feedback signal: Standard requires a valueMetric object with a mandatory linkedValueDriverIds[] foreign key to establish alignment between the pricing mechanism and the value model.
Criterion 1.3 — Tier and Package Structure (6 pts)
Score
Descriptor
6
All tiers declared as typed PricingTier objects with: tierName, price, currency, billingPeriod (enum: monthly, annual, event, outcome), includedEntitlements[] as typed capability objects, overageRules, and upgradeDowngradeLogic
5
Tiers typed with price, currency, billing period, and entitlements; overage rules or upgrade logic missing
4
Tiers typed with price and billing period; entitlements listed as untyped strings
3
Tiers present; entitlements and overage rules in prose only
2
Tiers described as an HTML or prose table not parseable as structured objects
1
Pricing described as a single price point
0
Absent
Criterion 1.4 — Volume, Discount, and Commitment Logic (6 pts)
Discounts and commitment schedules are among the most frequently misrepresented pricing elements for AI systems.
Score
Descriptor
6
Volume discount schedules declared as arrays of typed DiscountRule objects with {threshold, thresholdUnit, discountType (enum: percentOff, flatRate, newUnitPrice), discountValue}; commitment-based discounts typed separately; minimum commitment and ramp structures declared
5
Discount arrays present with threshold and value; discount type or threshold unit absent on ≤ 2 rules
4
Discount arrays present; discount type absent from most rules
3
Discount schedules present but encoded as prose ranges or narrative tables
2
Discounts mentioned without structure
1
“Contact us for pricing” or similar; no discount information
0
Absent
Criterion 1.5 — Outcome and Contingency Pricing Rules (6 pts)
For outcome-based and hybrid models, contingent pricing logic must be fully typed to be AI-computable.
Score
Descriptor
6
Contingent pricing conditions declared as typed PricingRule objects with: condition (structured predicate), measuredOutcome, outcomeUnit, price, currency, settlementMechanism; baseline and measurement methodology declared
5
Contingent rules typed; baseline or measurement methodology absent
4
Contingent rules typed but condition expressed as prose string
3
Outcome pricing described in structured annotations but not computable
2
Outcome pricing referenced in prose only
1
Not applicable — model type does not support contingent pricing (mark N/A; award 3 pts)
0
Absent for model types where it should be present
Dimension 2: Pricing Logic Computability (20 points)
Criterion 2.1 — Price Computation Completeness (7 pts)
An agent should be able to compute a price quote for a given configuration from the model alone, without calling an external API.
Score
Descriptor
7
Given all required inputs (tier selection, usage quantity, commitment term, applicable segment), the model provides sufficient structured data to compute an exact price; all pricing rules are typed conditionals, not prose; edge cases (free tier limits, overage caps, minimum charges) are typed
5–6
Most price paths computable; 1–2 edge cases in prose
3–4
Core tier prices computable; discount and overage logic requires inference
1–2
Prices readable but not computably derivable
0
Price computation impossible from structured data alone
Criterion 2.2 — Input Schema for Price Calculation (6 pts)
AI agents require a declared input schema to know what information to collect before computing a price.
Score
Descriptor
6
Model declares a PricingInputSchema with all required and optional inputs: type, unit, validation constraints (min, max, allowedValues), prompt text, and defaultValue; a worked example with inputs and computed price output is included
5
Input schema complete; worked example absent
4
Input schema present with types; validation constraints and prompt text missing
3
Required inputs listed as a string array; no types or constraints
2
Inputs implied by tier structure but not formally declared
1
No input schema
0
Absent
Feedback signal: Standard should define a PricingInputSchema object with required and optional inputs, types, constraints, and prompt text — parallel to the InputSchema in the value model standard.
Criterion 2.3 — Conditional and Segment-Specific Pricing (7 pts)
Many B2B pricing models include segment-specific adjustments that must be explicitly typed to avoid AI misapplication.
Score
Descriptor
7
All segment or geography-specific pricing variants declared as typed PricingVariant objects linked to CustomerSegment or geographic scope; conditionals structured as typed predicates, not prose; fallback/default pricing explicitly declared
5–6
Pricing variants typed; fallback pricing absent
3–4
Variants present as separate tier objects without explicit segment linkage
1–2
Variants described in prose; AI must infer applicability
0
No variant pricing; single universal price assumed
Dimension 3: Machine Parsability and Schema Integrity (15 points)
Criterion 3.1 — Syntactic Validity and Semantic Typing (5 pts)
Score
Descriptor
5
JSON syntactically valid; JSON-LD @context and @type declarations present; all types reference a declared namespace; numeric properties carry unitCode (UCUM or UN/CEFACT); currency values use ISO 4217 codes; no encoding errors
4
Valid JSON-LD; unitCode and ISO currency present on ≥ 80% of fields
3
Valid JSON; type labels as strings without namespace; no unitCodes
2
Ad hoc property names; no shared vocabulary; mixed types
1
Structured intent but non-parseable syntax
0
Not structured; HTML table, prose, or image only
Criterion 3.2 — Temporal Validity and Versioning (5 pts)
Stale pricing data is one of the most common causes of AI agent errors in vendor comparisons and procurement workflows.
Score
Descriptor
5
validFrom, validTo, schemaVersion, lastVerified, and supersedes link to prior version all present; model served at a stable canonical URL with application/ld+json content-type; CORS enabled; discoverable via llms.txt or well-known endpoint
4
validFrom, schemaVersion, and canonical URL present; validTo or supersedes absent
3
Publication date present; no validity window or schema version
2
Date in page metadata only; not in model schema
1
No temporal metadata
0
Absent
Feedback signal: Standard must require validFrom, schemaVersion, and canonicalUrl as mandatory fields. validTo, lastVerified, and supersedes strongly recommended.
Criterion 3.3 — Identifier Stability and Cross-Referenceability (5 pts)
Score
Descriptor
5
All entities (tiers, discount rules, pricing components, variants) carry stable @id URIs; valueMetric links to linkedValueDriverIds in the companion EVE model; model includes a provenance block with author, organization, and validation date
4
@id on all named entities; companion model linkage or provenance block partially present
3
Internal ID strings (e.g., “id”: “tier-001”) without namespace; no companion model linkage
2
No entity IDs; objects referenced positionally
1
No cross-referencing mechanism
0
Single flat object; no internal structure
Dimension 4: AI Reasoning Fidelity (15 points)
Criterion 4.1 — Answerable Business Question Coverage (8 pts)
Tests whether the representation supports the canonical pricing question set an AI agent is expected to answer without hallucination or inference errors.
Reference question set:
What is the price for [tier/configuration] billed [monthly/annually]?
How does price scale with [usage metric]?
What is the total cost of ownership over [12/36 months] for [customer profile]?
What discounts are available and under what conditions?
What are the switching or exit costs?
How does the price relate to the economic value delivered?
Are there segment-specific or geography-specific pricing variants?
Is this pricing current, and when was it last updated?
Score
Descriptor
8
All 8 questions answerable from structured data without AI inference beyond declared values
6–7
6–7 questions answerable
4–5
4–5 questions answerable
2–3
2–3 questions answerable
1
1 question answerable
0
None answerable from structured data
Feedback signal: Score profile across the 8 questions identifies exactly which structural elements are missing from the standard.
Criterion 4.2 — Ambiguity and Hallucination Risk (7 pts)
Evaluates how well the representation eliminates conditions that force AI systems to guess or fabricate pricing values.
Score
Descriptor
7
No ambiguous property names; all numeric values carry units; currency explicitly declared in ISO 4217; enumerations use closed controlled vocabularies; all conditional logic expressed as typed predicate objects, not prose; “contact us” pricing gaps are declared, not silently omitted
5–6
Units and currency present; ≤ 2 ambiguous property names or untyped conditionals
3–4
Some values undeclared in units; conditional pricing in prose
1–2
Frequent ambiguity; AI must make assumptions to compute prices
0
Representation designed for human readers only; AI hallucination risk is high
Scoring Summary
Dimension
Max
Score
1. Pricing Model Structural Completeness
30
/30
2. Pricing Logic Computability
20
/20
3. Machine Parsability and Schema Integrity
15
/15
4. AI Reasoning Fidelity
15
/15
Total
80
/80
Grade Thresholds
Grade
Score
Interpretation
A — Production-Ready
72–80
AI agents can compute price quotes and answer all canonical pricing questions reliably. Reference-quality implementation.
B — Answer Engine Ready
60–71
AI answer engines can address most pricing questions. Discount logic or input schema incomplete.
C — Partially Machine-Readable
44–59
Core pricing intent communicated; discount and conditional logic ambiguities create hallucination risk.
D — Human-Readable Only
28–43
Useful as a training source; not reliable for real-time agent or answer engine use.
F — Non-Compliant
0–27
Does not meet minimum structural requirements for AI consumption.
Minimum Viable Pricing Model (MVPM) Checklist
A representation must include all of the following to achieve a passing score (≥ 44):
@type: PricingModel with @context namespace declaration
pricingArchitecture enum field from the controlled vocabulary
valueMetric object with name and unit
At least one PricingTier object with price, currency, billingPeriod
includedEntitlements[] on each tier (may be empty array for usage-only models)
validFrom timestamp and schemaVersion string
canonicalUrl for the published model
Currency declared in ISO 4217
Evaluating Online Representations of EVE-Style Value Models
May 23, 2026
Purpose and Scope
This rubric evaluates how well a published EVE-style Economic Value Estimation model is structured for consumption by AI answer engines and AI agents. It scores a representation against four quality dimensions and generates feedback signals for improving the technical standard used to represent these models in JSON-LD or equivalent structured formats.
A well-formed value model must allow an AI to answer: What is the total economic value of this solution for a specific customer segment, and how is that value decomposed and justified?
Total score: 80 points. Each criterion includes a feedback signal that maps directly to a recommended change in the technical standard.
Dimension 1: EVE Structural Completeness (30 points)
Criterion 1.1 — Reference Value (NBCA) Representation (6 pts)
Evaluates whether the model includes a clearly identified Competitor Reference Value — the price or total cost of the Next Best Competitive Alternative (NBCA).
Score
Descriptor
6
NBCA explicitly typed as a ReferenceValue entity; carries amount, currency, unit; linked to a named competitive alternative via competitorId; includes a confidence attribute and a source citation
5
NBCA typed with value, currency, and unit; competitor linkage present; confidence absent
4
NBCA present and typed; competitor identity implied but not declared as a linked entity
3
NBCA present as a numeric field but not typed; no competitor linkage
2
NBCA present only in prose or annotation comments; not machine-addressable
1
NBCA partially implied by context
0
NBCA absent
Feedback signal: A score ≤ 3 triggers a standard-level requirement for a mandatory referenceValue object with required sub-properties: amount, currency, unit, competitorId, confidence.
Criterion 1.2 — Positive Differentiation Value (PDV) Driver Coverage (6 pts)
Evaluates completeness and granularity of value drivers contributing to PDV.
Score
Descriptor
6
All PDV drivers declared as typed ValueDriver objects with: name, category (enum: revenueEnhancement, costReduction, workingCapital, capexSavings, riskMitigation, flexibilityOptionality), formula, formulaVariables[] with types and units, and a computed resultValue
5
All drivers typed with formula and variables; one or more category enum values missing
4
All drivers present and typed; formula variable type or unit declarations missing on ≥ 1 driver
3
Drivers present but mixed between structured objects and prose strings
2
PDV stated as a single aggregate number with no driver decomposition
1
PDV referenced without breakdown
0
PDV absent
Feedback signal: A score ≤ 3 signals the standard needs a typed ValueDriver array schema with required sub-properties: driverType (enum), formula, formulaVariables[], and resultValue.
Criterion 1.3 — Negative Differentiation Value (NDV) Coverage (6 pts)
Evaluates whether switching costs, training costs, integration costs, and competitor PDV offsets are explicitly modeled.
Score
Descriptor
6
All NDV components declared as typed objects (switching cost, integration cost, training cost, competitor PDV offset), each with amount, currency, unit, and recurrenceType (enum: oneTime, recurring)
5
NDV components present and valued; recurrence type missing from ≤ 1 item
4
NDV components present and valued; recurrence type absent from ≥ 2 items
3
NDV present as a single aggregate or partial list
2
NDV mentioned in annotations but not structured
1
NDV acknowledged but not quantified
0
NDV absent
Feedback signal: A score ≤ 3 triggers a required negativeDifferentiationValue array with typed cost objects in the standard.
Criterion 1.4 — Net Differentiation Value and Pricing Range (6 pts)
Evaluates whether Net Differentiation Value (PDV − NDV) is explicitly stated and whether a value-based pricing range is derived from it.
Score
Descriptor
6
netDifferentiationValue computed from declared PDV and NDV component IDs; a pricingRange object with floor and ceiling is declared relative to NBCA; the full computation chain is traceable via entity references
5
Net value present with pricing range; computation chain partially traceable
4
Net value present with pricing range; computation chain not traceable
3
Net value present; pricing range absent or expressed informally
2
Net value stated without derivation linkage to components
1
Net value implied from context only
0
Absent
Feedback signal: Standard should require a netDifferentiationValue computed field with sourceComponentIds[] references and an optional pricingRange object with floor and ceiling.
Criterion 1.5 — Customer Segment and Use-Case Scoping (6 pts)
EVE models are customer-segment-specific; a model without segment binding is ambiguous for AI reasoning.
Score
Descriptor
6
Target segment(s) declared as typed CustomerSegment objects with attributes (industry, firmographicSize, usageProfile, geographicRegion); all value driver formula variables include segment-specific overrides or ranges
5
Segment object present with typed attributes; driver-level variable overrides absent
4
Segment declared at model level only; no typed attributes
3
Segment described in prose fields only
2
Segment implied by product name or solution context
1
No segment information
0
Model claims universal applicability with no segmentation
Feedback signal: Standard should require CustomerSegment as a first-class entity with typed attributes, linked to each ValueDriver formula variable set.
Dimension 2: Formula Representation and Computability (20 points)
Criterion 2.1 — Formula Expression Quality (7 pts)
Value driver formulas are the core computational logic of an EVE model; they must be machine-executable, not merely descriptive.
Score
Descriptor
7
Formulas expressed as structured expression objects (expression tree, JSON-formula, string template with typed variable references, or MathML); all variables declared with name, type, unit, defaultValue, and valueSource (enum: customerInput, benchmark, productSpec); formula result independently verifiable
6
String templates with typed variable declarations; result verifiable
5
String templates with variable names; types or units missing on ≤ 2 variables
4
String templates with variable names; types and units largely absent
3
Formula described in structured prose (e.g., “labor cost per call multiplied by call reduction rate”)
2
Formula result stated without derivation
1
Value drivers described conceptually without formula
0
Absent
Feedback signal: Standard should define a FormulaExpression type supporting at minimum string templates with typed variable references (formulaVariables[]), with an upgrade path to executable expression trees.
Criterion 2.2 — Uncertainty and Confidence Representation (6 pts)
Value models inherently contain estimates; AI systems must not present estimates as certainties.
Score
Descriptor
6
All estimated values carry a confidence field (enum: measured, benchmarked, estimated, assumed); ranges or distributions declared where point estimates are not defensible; all data sources cited with URI or reference identifier
5
Confidence levels present; source citations partially present (≥ 50% of drivers)
4
Confidence levels present; source citations sparse
3
Some values marked as estimated; no formal confidence vocabulary
2
Estimates and measured values indistinguishable in structure
1
No uncertainty representation
0
Values presented as absolute facts with no uncertainty signal
Feedback signal: Standard must require a confidence enum on all value driver variables and formula results. Critical for RL reward modeling: AI should be penalized for presenting low-confidence estimates as facts.
Criterion 2.3 — Worked Examples and Parameterization (7 pts)
Agents need to substitute customer-specific variables to compute personalized value estimates; worked examples anchor AI reasoning.
Score
Descriptor
7
Model declares an InputSchema listing all required and optional customer inputs with types, validation constraints, and prompt text; ≥ 1 fully worked example with all variable values filled and result shown; example is linked to a named customer segment
6
Input schema present; worked example present but not linked to a segment
5
Input schema present; no worked example
4
Variable declarations present (types and defaults); no input schema or worked example
3
Variable names present; types and defaults missing; no worked example
2
Variables embedded in formula strings without structured declarations
1
No parameterization support
0
Absent
Feedback signal: Standard should define an InputSchema object — analogous to a function signature — with required and optional customer inputs, types, constraints, and prompt text.
Dimension 3: Machine Parsability and Schema Integrity (15 points)
Criterion 3.1 — Syntactic Validity and Semantic Typing (5 pts)
Score
Descriptor
5
JSON syntactically valid; JSON-LD @context and @type declarations present; all types reference a declared namespace (custom ontology or schema.org extension); numeric properties carry unitCode (UCUM or UN/CEFACT); no encoding errors
4
Valid JSON-LD; unitCode present on ≥ 80% of numeric fields
3
Valid JSON; type labels as strings without namespace; no unitCodes
2
Ad hoc property names; no shared vocabulary
1
Structured intent but non-parseable syntax
0
Not structured; HTML, prose, or image only
Criterion 3.2 — Identifier Stability and Traceability (5 pts)
AI agents navigating multi-document environments require stable, dereferenceable identifiers to trace claims back to source data.
Score
Descriptor
5
All entities carry stable @id URIs; value drivers, segments, and component references are individually addressable; foreign key references resolve to real entity IDs; provenance block present with author, organization, validation date, and methodology reference
4
@id on all named entities; provenance block partially complete
3
Internal ID strings without namespace; provenance block at model level only
2
No entity IDs; objects referenced positionally; model-level authorship only
1
No cross-referencing or provenance
0
Single flat object; no internal structure or provenance
Criterion 3.3 — Temporal Validity and Versioning (5 pts)
Score
Descriptor
5
validFrom, validTo, schemaVersion, lastVerified, and supersedes link present; model served at a canonical URL with application/ld+json content-type; discoverable via llms.txt or well-known endpoint
4
validFrom, schemaVersion, and canonical URL present; validTo or supersedes absent
3
Publication date present; no validity window or version declared
2
Date in page metadata only, not in model schema
1
No temporal metadata
0
Absent
Dimension 4: AI Reasoning Fidelity (15 points)
Criterion 4.1 — Answerable Business Question Coverage (8 pts)
Tests whether the representation supports the canonical value-question set an AI agent is expected to answer without hallucination.
Reference question set:
What is the total economic value of this solution for [customer segment]?
What is the value justification for the price?
How does the value compare to the next best competitive alternative?
Which value drivers contribute most to the ROI?
What are the switching costs and negative value components?
How sensitive is the value estimate to changes in key assumptions?
What data sources and confidence levels underpin the value estimates?
Has this model been validated, and when was it last updated?
Score
Descriptor
8
All 8 questions answerable from structured data without AI inference beyond declared values
6–7
6–7 questions answerable
4–5
4–5 questions answerable
2–3
2–3 questions answerable
1
1 question answerable
0
None answerable from structured data
Feedback signal: Score profile across the 8 questions identifies exactly which structural elements are missing from the standard.
Criterion 4.2 — Ambiguity and Hallucination Risk (7 pts)
Evaluates how well the representation eliminates conditions that force AI systems to guess or fabricate values.
Score
Descriptor
7
No ambiguous property names; all numeric values carry units; enumerations use closed vocabularies; currency explicitly declared; conditional overrides represented as typed rule objects, not prose
5–6
Units and currency present; ≤ 2 ambiguous property names or untyped conditionals
3–4
Some values undeclared in units; conditional logic in prose
1–2
Frequent ambiguity; AI must make assumptions to answer basic questions
0
Representation designed for human readers only; AI hallucination risk is high
Scoring Summary
Dimension
Max
Score
1. EVE Structural Completeness
30
/30
2. Formula Representation and Computability
20
/20
3. Machine Parsability and Schema Integrity
15
/15
4. AI Reasoning Fidelity
15
/15
Total
80
/80
Grade Thresholds
Grade
Score
Interpretation
A — Production-Ready
72–80
AI agents can reliably simulate value and answer all canonical business questions. Reference-quality implementation.
B — Answer Engine Ready
60–71
AI answer engines can address most value questions. Parameterization or formula traceability incomplete.
C — Partially Machine-Readable
44–59
Core EVE intent communicated; significant ambiguity or missing formulas create hallucination risk on derived questions.
D — Human-Readable Only
28–43
Useful as training source; not reliable for real-time AI consumption.
F — Non-Compliant
0–27
Does not meet minimum structural requirements for AI consumption.
Minimum Viable Value Model (MVM) Checklist
A representation must include all of the following to achieve a passing score (≥ 44):
@type: EVEModel with @context namespace declaration
referenceValue object with amount, currency, unit
valueDrivers[] array with ≥ 1 typed driver including formula and resultValue
negativeDifferentiationValue[] with ≥ 1 typed cost component
netDifferentiationValue numeric field
customerSegment object with ≥ 1 typed attribute
confidence field on ≥ 1 formula variable
validFrom timestamp and schemaVersion string
canonicalUrl for the published model
Use in Reinforcement Learning
When used as a reward signal in RLHF or RLVR pipelines:
Criterion 4.1 maps directly to a ground-truth Q&A set. Generate answers to the 8 reference questions from the structured data; score correct vs. hallucinated answers as verifiable binary rewards.
Criterion 4.2 is the most operationalizable single reward signal: probe the model with 5–10 questions and penalize any AI output that introduces values not declared in the schema.
Criterion 2.2 supports reward shaping against overconfidence: train the AI to distinguish measured from estimated confidence levels and hedge outputs accordingly.
Use the rubric as a cognitive scaffold for an LLM judge rather than as a rigid checklist summed mechanically — holistic rubric-conditioned scoring consistently outperforms simple criterion aggregation in reward modeling research.
Relationship Between the Pricing Model and Value (EVE) Model Rubrics
A pricing model achieves maximum value for AI systems when it is paired with a companion EVE value model. The following cross-rubric linkages are recommended as optional but high-value fields in the standard:

One of the more technical pieces I've read this week, but a necessary one.
If I had to distill it to one sentence: most pricing models are built for human consumption and don't translate to AI consumption. The gap between the two is bigger than most people realize.
What struck me most is that this isn't really a pricing problem. It's a data infrastructure problem dressed up as one. The pricing logic might be perfectly sound but if it can't be read, computed, or compared by an agent, it effectively doesn't exist for that use case.
Curious how far away you think we are from AI buying agents being common enough that this becomes urgent for most businesses.