
Credit-Based Pricing Execution Patterns: Analysis of the Tanso Dataset
A snapshot in June 2026

Part of a five part series to help you make key design decisions on credit based pricing.
A decision tree and checklist for credit based pricing design
Credit-Based Pricing Execution Patterns: Analysis of the Tanso Dataset (this post)
Metrics for credit based pricing models (in preparation)
TL;DR
Tanso’s June 2026 data confirms a bifurcated landscape: a minority of credit-native designs (30–35% of products) vs. a large majority still trapped in subscription-seat + hard caps, especially at the AI application layer.
Only 23 of 73 companies (31%) score 4–5 on the credit-native index, and these are overwhelmingly API/infrastructure vendors; most AI apps are still in transitional or “credits in name only” designs.
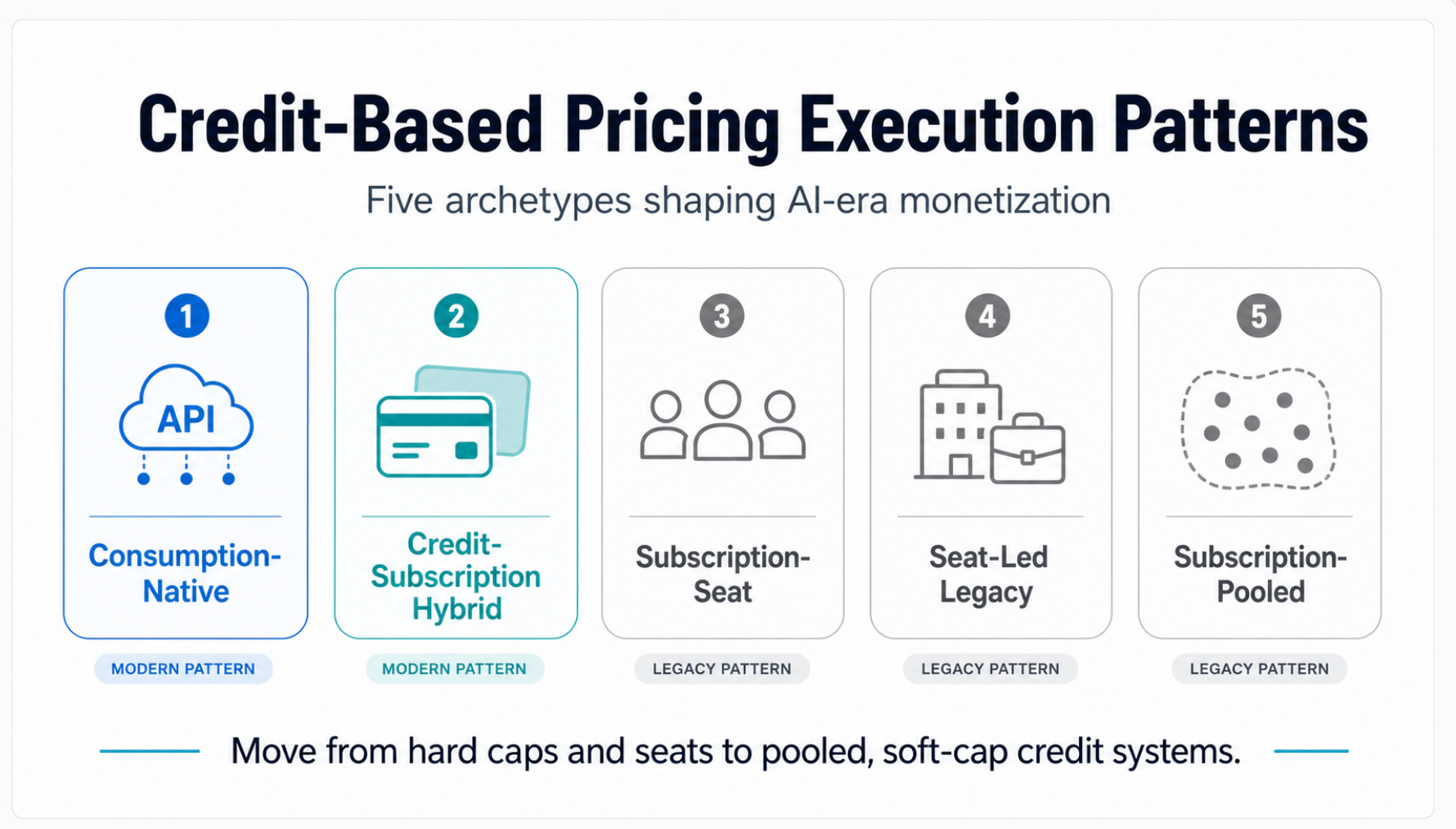
Five execution patterns have crystallized:
Consumption-Native (API-first)
Credit-Subscription Hybrid (vanguard)
Subscription-Seat (traditional SaaS)
Seat-Led (legacy B2B)
Subscription-Pooled (emerging hybrid)
The strategic opportunity is to move from Subscription-Seat into Hybrid and Pooled architectures without losing revenue predictability.
The most coherent designs (Anthropic API, Snowflake, Databricks, ElevenLabs, Replit, Clay, Windsurf) combine: pooled allocation, soft caps or rollover, PayGo, top-ups, and abstract credits, consistently scoring 4–5 on the credit-native index and setting the template for agent-economy pricing.
Hard Caps are the primary anti-pattern: 45% of companies still stop usage at zero credits, with the strongest concentration in subscription-seat AI apps (P(Hard Cap | Subscription) ≈ 0.74), creating the worst possible experience for agentic workflows mid-execution.
Action: Replace Hard Cap + No Pay as you Go with “auto-top-up + alert” as your default overage design; treat hard stops as an exception for compliance or abuse cases, not the norm.
Abstract credits are necessary but not sufficient: 12 companies use credits as the metric, but credit-native scores for this group range from 0 to 5; Jasper, v0, and others demonstrate that “credits layered on a seat subscription skeleton” just replicates old quota behavior with new labels.
Action: Never ship abstract credits without simultaneously redesigning lifecycle policies (overage, rollover, pooling); treat unit design (C1) and lifecycle core (C5–C8) as a single decision, not two separate projects.
Rollover is scarce (14% of companies) but highly correlated with maturity: it clusters in the most credit-native designs (Anthropic, OpenAI, ElevenLabs, Replit, Clay, Snowflake, Databricks, BigQuery, Windsurf) and is entirely absent from AI productivity subscriptions.
Action: Implement capped rollover for paid tiers (e.g., up to 1× period allowance, expiring within 12 months) and socialize the revenue-recognition story with finance as “committed credit pool ARR,” rather than defaulting to “no rollover” to appease accounting.
Pooling is the hinge constraint: 100% of consumption-revenue companies are pooled, but only 13% of subscription companies pool; future hybrids will win by combining subscription revenue with pooled credits (Clay, ElevenLabs) rather than clinging to per-seat allocation.
Action: Add pooling before rollover; design a shared organizational credit inventory first, then layer rollover on the pool to avoid stranded, individual-level credit overhang.
Category signal: AI video and most AI voice vendors are converging on subscription-seat + hard cap, trading UX and value alignment for “prosumer simplicity,” while vibe coding tools (Replit, Windsurf, Lovable, Bolt, v0) are setting the new standard with abstract credits, pooling, soft caps, and rollover.
Action: If you are in a high-compute, multi-use-case category (coding, data, agents), treat Replit–Windsurf–Snowflake–Databricks as your reference set; if you look more like “AI video” (subscription-seat, hard cap, no rollover), you are likely under-monetizing and over-exposing yourself to the “AI tax.”
Governance is the missing layer in the dataset and the next competitive frontier: mature designs are converging on real-time credit wallets, simulators, alerts, and transparent draw-order, but these capabilities are rarely described publicly today.
Action: Start now on governance UX (dashboards, FEFO draw order, budget controls) and publish machine-readable pricing/entitlement schemas (e.g., via The Value Project JSON standard) so buyer agents and procurement systems can reason about your model.
Strategic forward view: by 2027,
adoption of rollover rates will roughly double
pooling will climb toward 50–60%
hard caps to decline as hybrid credit-subscription architectures become the default for serious AI applications
Tanso has updated its dataset on how companies are pricing and what choices they are making on key pricing design decisions. They now cover 73 companies (June 2026). This data set is unique in that it looks at actual pricing and credit design decisions across a range of AI native and AI adapting companies (companies adding AI chatbots and agents to existing functionality).
We (Steven Forth and Michael Mansard) mapped this data against the Credit Based Pricing Design Structure Matrix that we introduced in Emerging patterns in credit based pricing design: Credit Based Pricing for the Agent Economy Part 1.
The data shows five coherent design patterns, a set of near-universal co-occurrence rules, and a cluster of “rare combination” anti-patterns. Only 23 companies (31%) score 4 or 5 on a five-dimension credit-native index, and they are overwhelmingly API-layer infrastructure providers. The majority of AI application-layer vendors are still in early-stage or transitional pricing designs. The data also surface three emerging tensions that will shape design patterns through 2027: the abstraction-level trap (infrastructure metrics vs. value-anchored credits), the pooling-rollover tradeoff, and the Hard Cap defaults that undermine the trust-transparency goals the framework identifies as foundational.
The Dataset — Structure and Scope
The Tanso dataset captures pricing design choices across 73 products spanning 18 categories. The columns correspond directly to key lifecycle design variables in the DSM:

The distribution across categories is AI-heavy: 47 of 73 companies (64%) fall into one of seven AI-specific categories (AI API, AI Coding, AI Design, AI Productivity, AI Video, AI Voice, AI Search). This reflects the Tanso focus on AI monetization and makes it directly relevant to agent economy pricing questions.
Revenue model split across the full dataset:
Subscription Revenue: 39 companies (53%)
Consumption / Usage Revenue: 22 companies (30%)
Seat Expansion: 10 companies (14%)
Transaction Fees: 2 companies (3%)
The distribution is important context: the dataset is not predominantly credit-native. More than half the companies are subscription-first, and 14% are still seat-expansion businesses. The 30% consumption-revenue cluster is where credit-native design is most fully realized.
Here are some snapshots of the Tanso June 2026 data.
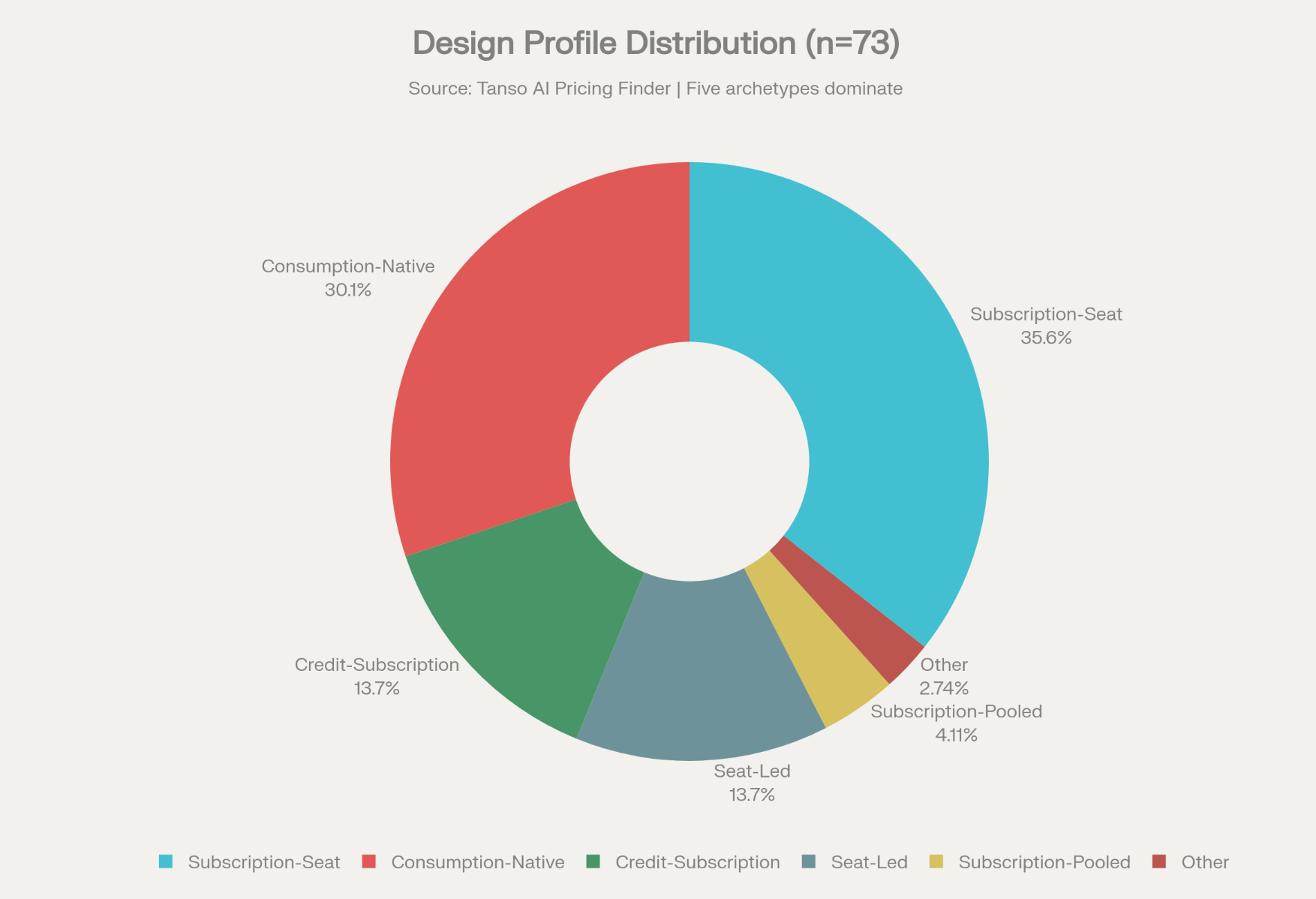
Seat based pricing is still the most common pricing model, even among these companies, but its dominance is fading.
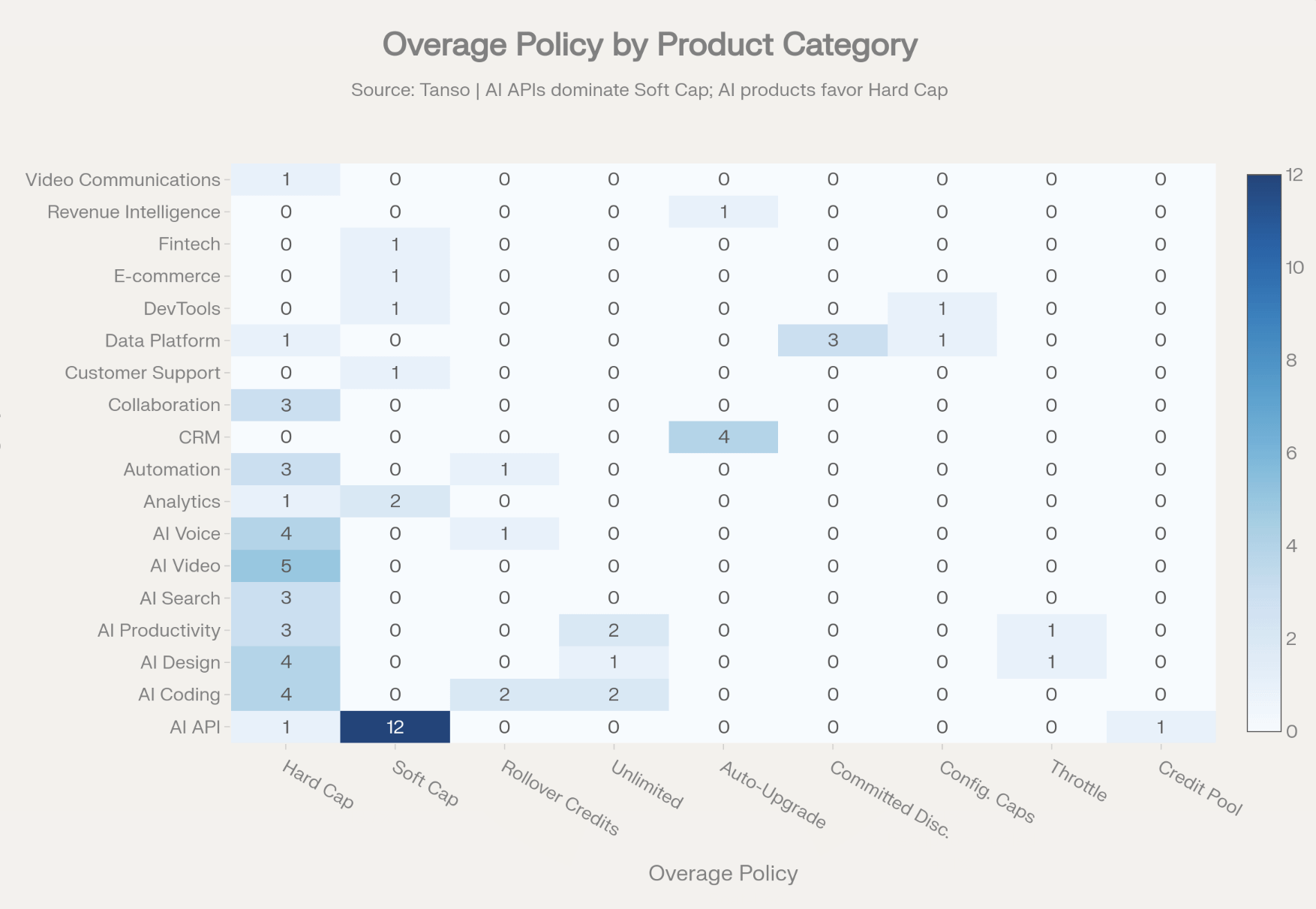
Outside of the AI API companies Hard Caps where usage stops once credits are expended. We think this is close to being an anti-pattern. Be generous with your users and they will repay you with loyalty and by buying more credits.
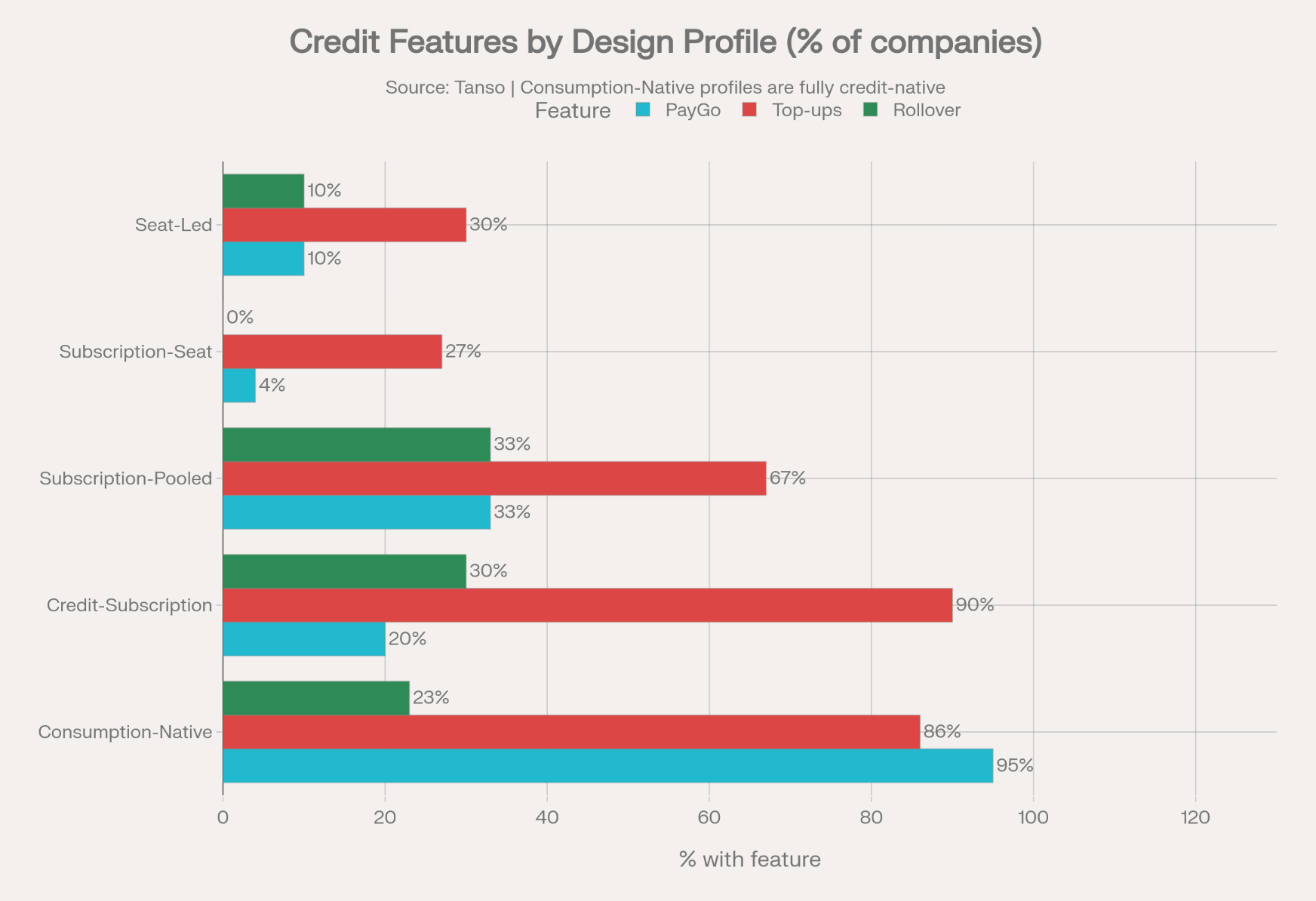
PayGo is short for Pay as you Go or just buy the credits you need when you need them. This will become the standard, though these credits will be sold at a premium to subscription credits (there is a lot of variation here, from a 10% premium to a 100% premium).
Five Design Patterns
Insert image
Running the Tanso dataset through the DSM lens finds five design patterns. These help to extend the work done to date and ground it in current practices.
Consumption-Native (API-First)
22 companies, 30%
Examples: OpenAI, Anthropic (Claude API), AWS Bedrock, Azure OpenAI, Google Gemini API, Mistral, Cohere, Groq, Fireworks AI, Together AI, Replicate, Twilio, Stripe, Snowflake, Databricks, BigQuery, MongoDB Atlas, Supabase, Vercel
Design signature:
Revenue: Consumption/Usage 100%
Metric: Tokens or compute-level infrastructure metrics 82%
Overage: Soft Cap with Overage Charges 68%, Committed Use Discounts 14%, Configurable Spend Caps (9%)
Rollover: 23% carry credits forward
Top-ups: 86% offer top-ups
Pay as you Go: 95%
Seat Pool: 100% Pooled
Credit-native score: 4.2 average (highest of all archetypes)
This is the most fully realized credit-based pricing group in the dataset. The defining combination is Consumption Revenue + Pooled + Soft Cap + Pay as you Go + Top-ups — a cluster that appears in 14 of the 22 companies with almost no deviation. The logic follows Foundation Choice C3 in the DSM (subscription architecture = pure consumption) drives Lifecycle Core C5 (soft cap rather than hard stop) and makes C7 (pooling) the natural allocation mechanism. Pay as you Go and Top-ups are structural consequences of a consumption model, not bolt-on features.
The dominant metric at this layer is tokens (input/output), present in 11 of 14 AI API companies. This is a Low (Infrastructure) abstraction level in the framework’s unit design hierarchy — positioned at the bottom of the value chain, decoupled from business outcomes. The strategic implication is that token pricing is “legible” to technical buyers but “nearly invisible” to business buyers because it maps to compute cost rather than economic value. The entire AI API cluster is pricing at C1 (unit design) against cost and use alignment, not value alignment — which the framework identifies as a second-best design except for purely technical buyer segments.
The exception in this archetype is Anthropic (Claude API), which uses “Credit Pool / Prepaid Balance” as its overage mechanism, combined with carry rollover — making it the single most fully-designed credit system in the dataset, scoring 5/5 on the credit-native index. Snowflake and Databricks also score 5/5, using abstract credits as the metric rather than raw tokens, and deploying committed-use discounts as the overage mechanism — a design that shifts the consumption model toward committed-pool architecture and signals more sophisticated enterprise pricing.
Credit-Subscription Hybrid (The Vanguard)
10 companies, 14%
Examples: ElevenLabs, Replit, Windsurf (Codeium), Clay, v0 (Vercel), Adobe Firefly (partial), Canva (partial), HeyGen, Pika, Runway
Design signature:
Revenue: Subscription 100%
Metric: Credits (Abstract Unit) — 80%
Overage: Hard Cap (70%), Rollover Credits (30%)
Rollover: 30% carry
Top-ups: 90% offer top-ups
PayGo: 20%
Seat Pool: 40% Pooled, 60% Per Seat
Credit-native score: 3.5 average
This is the most strategically interesting pattern — and arguably the leading indicator of where credit-based pricing is heading for AI application-layer vendors. These companies have made the key Unit Design choice (C1) to use abstract credits rather than infrastructure metrics. Abstract credits allow variable credit weights per action, decouple pricing from underlying token costs, and create legible value stories for non-technical buyers.
ElevenLabs is the clearest exemplar: subscription revenue base, Credits (Abstract Unit) metric, Rollover Credits overage policy, carry rollover, top-ups, PayGo, and pooling — the only voice AI company that achieves a 5/5 credit-native score. Replit replicates this design exactly in the AI Coding category. These two companies demonstrate what the Forth–Mansard framework predicts should emerge: a subscription base (providing revenue predictability) layered with abstract credits (providing value alignment) and generous lifecycle policies (rollover, pooling) that create buyer trust and reduce churn risk.
Windsurf (Codeium) represents a slightly different variant: abstract credits, rollover, top-ups, but no PayGo and still per-seat allocation. This hybrid signals a company in transition — it has adopted the right unit design (abstract credits) and rollover policy but has not yet moved to pooled allocation, keeping it constrained within a seat mental model even while using a more sophisticated credit metric.
The 30% of this archetype using “Rollover Credits” as their overage mechanism (rather than hard cap) is a notable design choice: it is technically a form of borrowing from future period credits as a response to overage — a more buyer-friendly approach than service termination. Overage and rollover should be designed to work together and not separate policies.
Subscription-Seat (Traditional SaaS)
26 companies, 36%
Examples: ChatGPT Plus, Claude Pro, Jasper, Make, Zapier, Perplexity, Kagi, You.com, Otter.ai, Fireflies.ai, Synthesia, Descript, HeyGen (consumer tier), Framer, Uizard, Amazon Q Developer, Sourcegraph Cody, Tabnine, Loom, Mem
Design signature:
Revenue: Subscription (100%)
Metric: Varied — messages, searches, transcription minutes, seats, abstract credits
Overage: Hard Cap (77%), Unlimited Fair Use (15%), Throttle (8%)
Rollover: 0% carry
Top-ups: 27%
Pay as you Go: 4%
Seat Pool: 100% Per Seat
Credit-native score: 0 average
This is the largest archetype by count and represents traditional SaaS pricing applied to AI products. The defining characteristic is the combination of Hard Cap + No Rollover + No PayGo + Per Seat — a cluster that occurs in 20 of the 26 companies with near-perfect consistency. The conditional probability P(Hard Cap | Subscription Revenue) = 0.74, making this the strongest co-occurrence rule in the entire dataset.
The design logic here is buyer-side cost control: hard caps give finance teams spending predictability. But from the framework perspective, this is a design failure on multiple dimensions. Hard caps with no Pay as you Go, no rollover, and no pooling mean that customers who run out of credits mid-period are simply blocked — creating what This is the worst possible trust and experience outcome. Hard ceiling: usage stops at zero credits should be paired with at minimum a top-up mechanism or auto-top-up alert.
To do otherwise will come to be seen as an anti-pattern or dark pattern in the future, a vestige of millennial style SaaS pricing.
The consumer-facing AI productivity sub-group (ChatGPT Plus, Claude Pro, Jasper, Perplexity, Kagi) is particularly notable: these are B2C or prosumer applications where the subscription model is deliberately simple (flat fee, no overages, hard cap as a quality-of-service guarantee rather than a revenue mechanism). This is a coherent choice. Credit-based pricing is inappropriate if your different agents or products have different buyers who value the outcomes in different ways or if you have only one agent or product, with just one use case. For these simple, single-purpose products, the hard cap + no rollover design is strategically sound even if it is credit-naive.
The concerning sub-group is the AI application vendors (Jasper, Make, Zapier, n8n, Descript, Synthesia) that have high compute costs and multiple use cases but are still using subscription-seat + hard cap models. These are the companies most exposed to the “AI tax”: as compute costs grow, hard-cap subscription models cannot absorb margin pressure, and these vendors will face either margin erosion or repricing trauma.
Seat-Led (Legacy B2B)
10 companies, 14%
Examples: Salesforce, HubSpot, Pipedrive, Zoho CRM, Gong, Linear, Notion, Slack, Figma, Intercom
Design signature:
Revenue: Seat Expansion (100%)
Metric: Seats/Users or Contacts/Records
Overage: Auto-Upgrade to Next Tier (50%), Hard Cap (30%), Unlimited Fair Use (10%)
Rollover: 10%
Top-ups: 30%
PayGo: 10%
Seat Pool: 100% Per Seat
Credit-native score: 0.4 average
This group is included in the Tanso dataset as a baseline comparison — these are established SaaS businesses where the seat-expansion model is intentional and coherent. Auto-upgrade to the next tier as the primary overage mechanism is a sophisticated design: it converts usage pressure into expansion revenue without billing complexity. The conditional probability P(Auto-Upgrade | Seat Expansion) = 0.50 (five of ten seat-expansion companies use this mechanism).
The strategic relevance to credit-based pricing is indirect but important: several companies in this group (Salesforce, HubSpot, Intercom (now to become part of Salesforce) are actively layering AI agent capabilities on top of their seat-based pricing infrastructure — Salesforce Agentforce being the canonical example of mixing seat pricing with credit-based AI agent consumption. The Seat-Led archetype is thus the primary source of future hybrid designs where credits are added to an existing seat-priced infrastructure rather than replacing it.
Subscription-Pooled (Emerging Hybrid)
3 companies, 4%
Examples: Clay, n8n, Hugging Face
This is the smallest and most interesting archetype — a transitional design where subscription revenue is combined with pooled credit allocation but without full consumption pricing. Clay is the clearest exemplar: Subscription Revenue + Enrichments/Lookups metric (activity-based) + Rollover Credits overage + carry rollover + top-ups + pooling. This achieves a credit-native score of 4, matching the API-layer leaders, while maintaining a subscription revenue model — demonstrating that the two are not mutually exclusive.
The rarity of this archetype (only 3 companies) suggests it is either an emerging pattern or a transitional state between Subscription-Seat and the more fully realized Credit-Subscription hybrid.
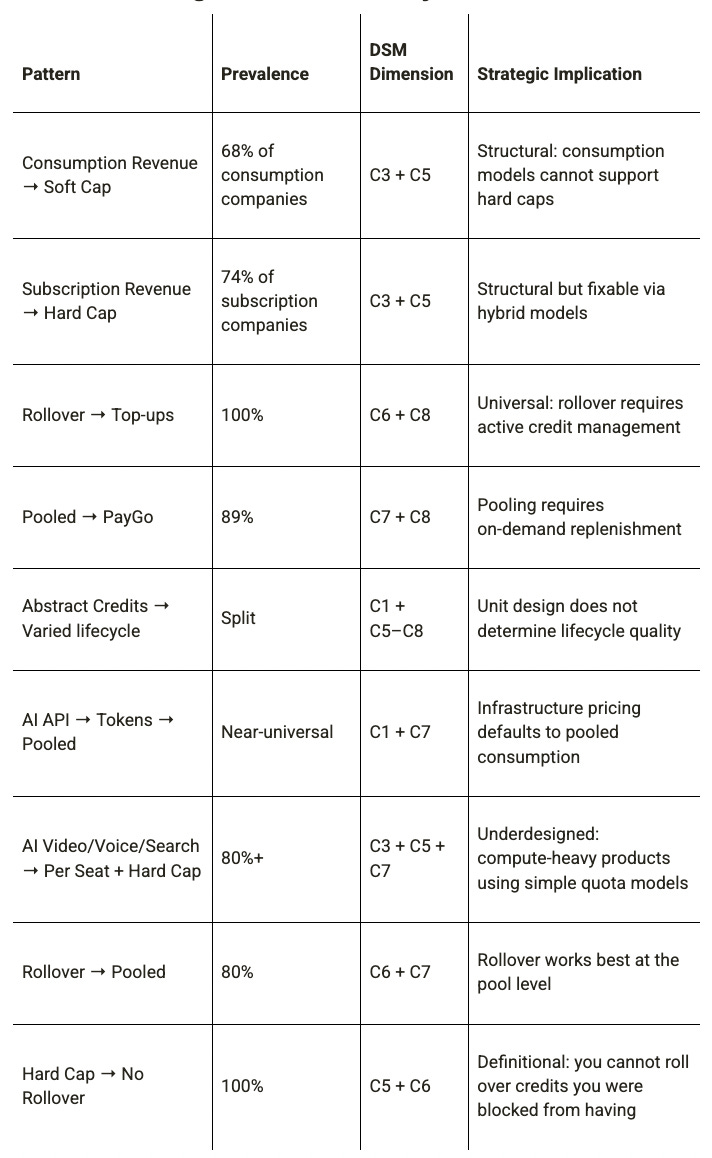
Co-Occurrence Rules — What Goes Together and What Doesn’t
Near-Universal Co-Occurrence Rules (conditional probability ≥ 0.80)
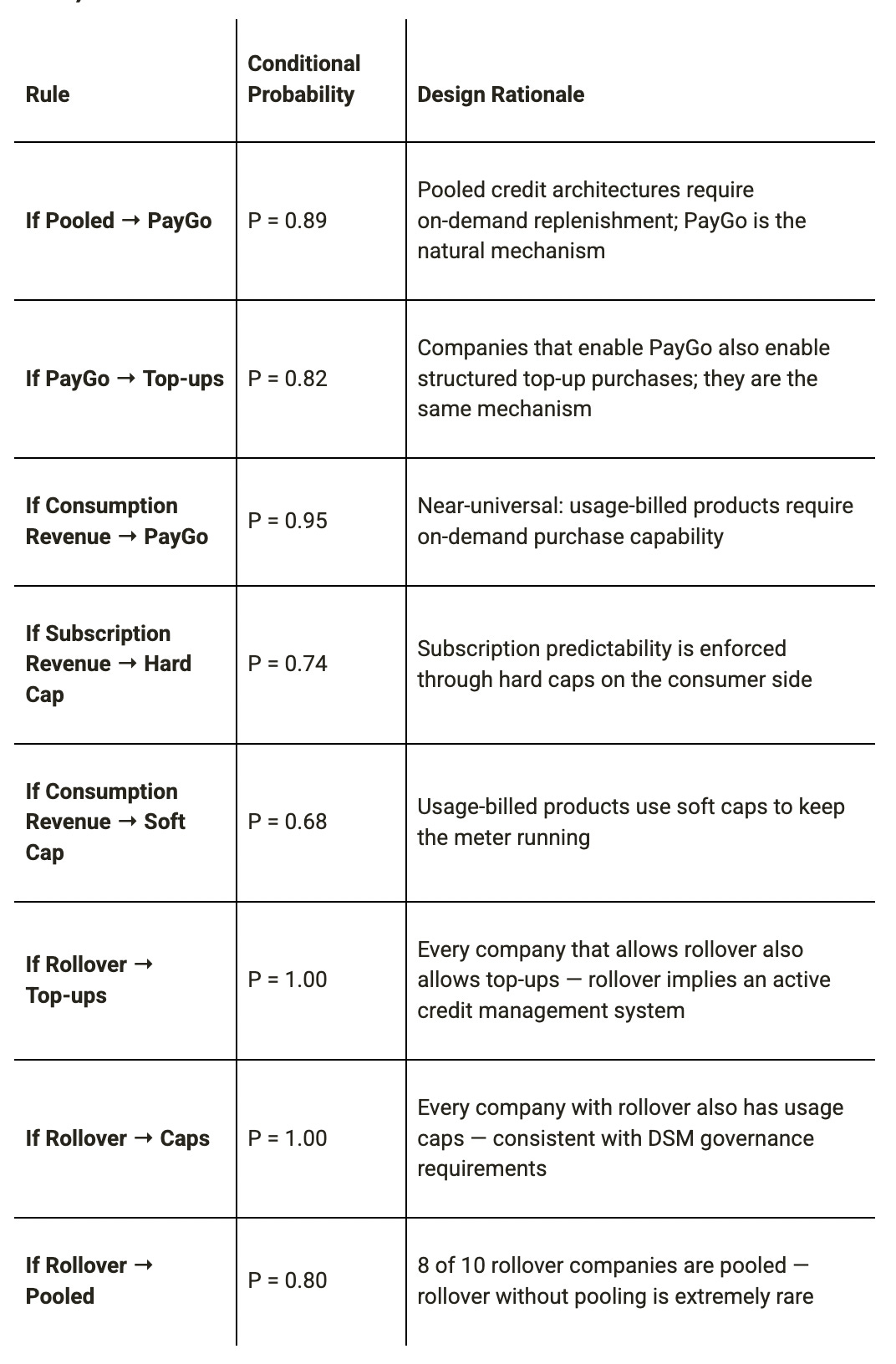
Strong Negative Co-Occurrences (rare or absent combinations)
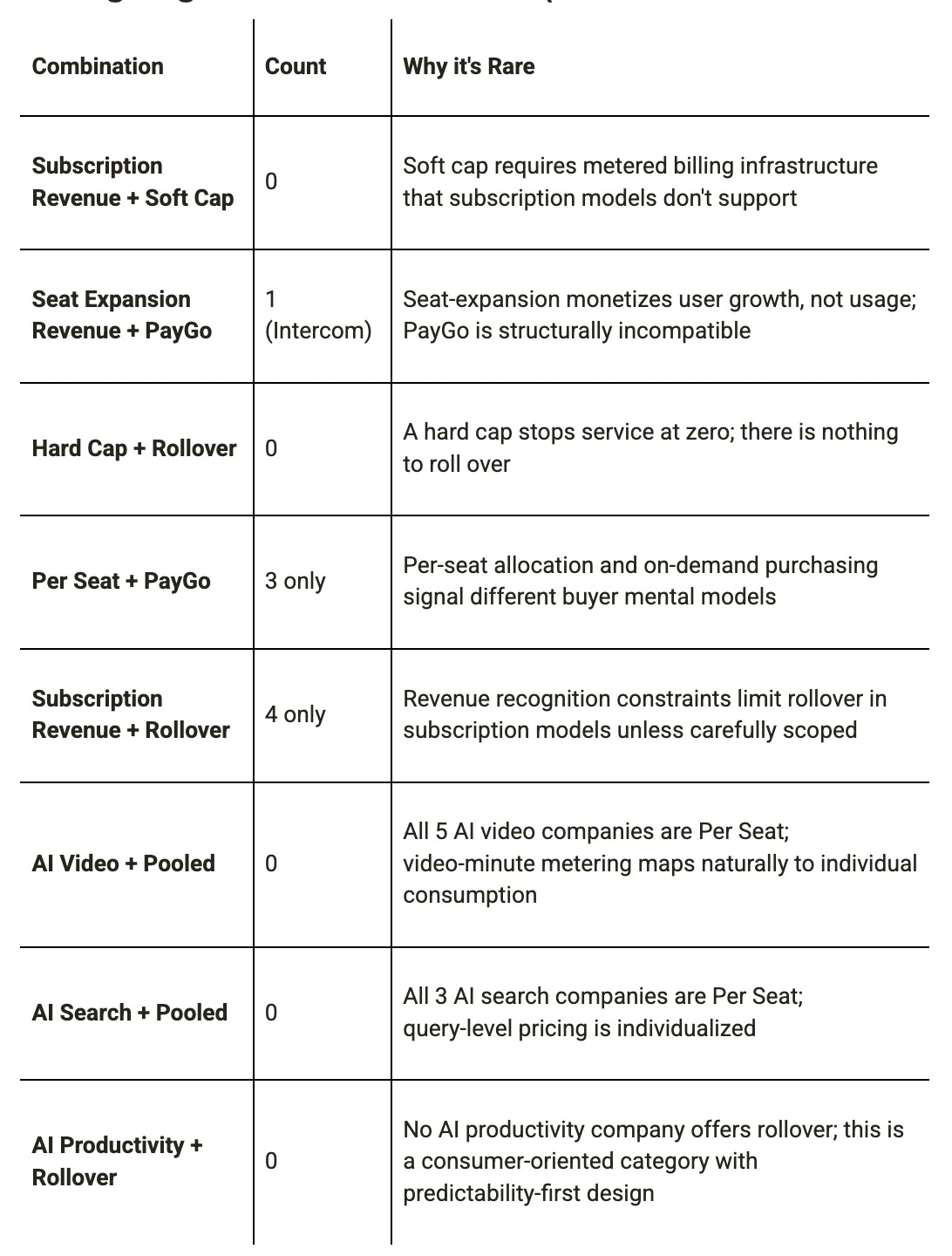
No AI productivity company offers rollover; this is a consumer-oriented category with predictability-first design.
The absence of Subscription Revenue + Soft Cap means that subscription-priced products never charge for overage. They either stop service (Hard Cap), degrade it (Throttle), or declare unlimited fair use. This reflects that subscription contracts are structured as flat-rate commitments, and overage billing would require metered infrastructure that subscription pricing doesn’t have. The implication is that companies that want both subscription revenue predictability and overage capture must restructure their revenue model toward hybrid consumption pricing, not just add overage to an existing subscription.
Design Tensions Revealed by the Data
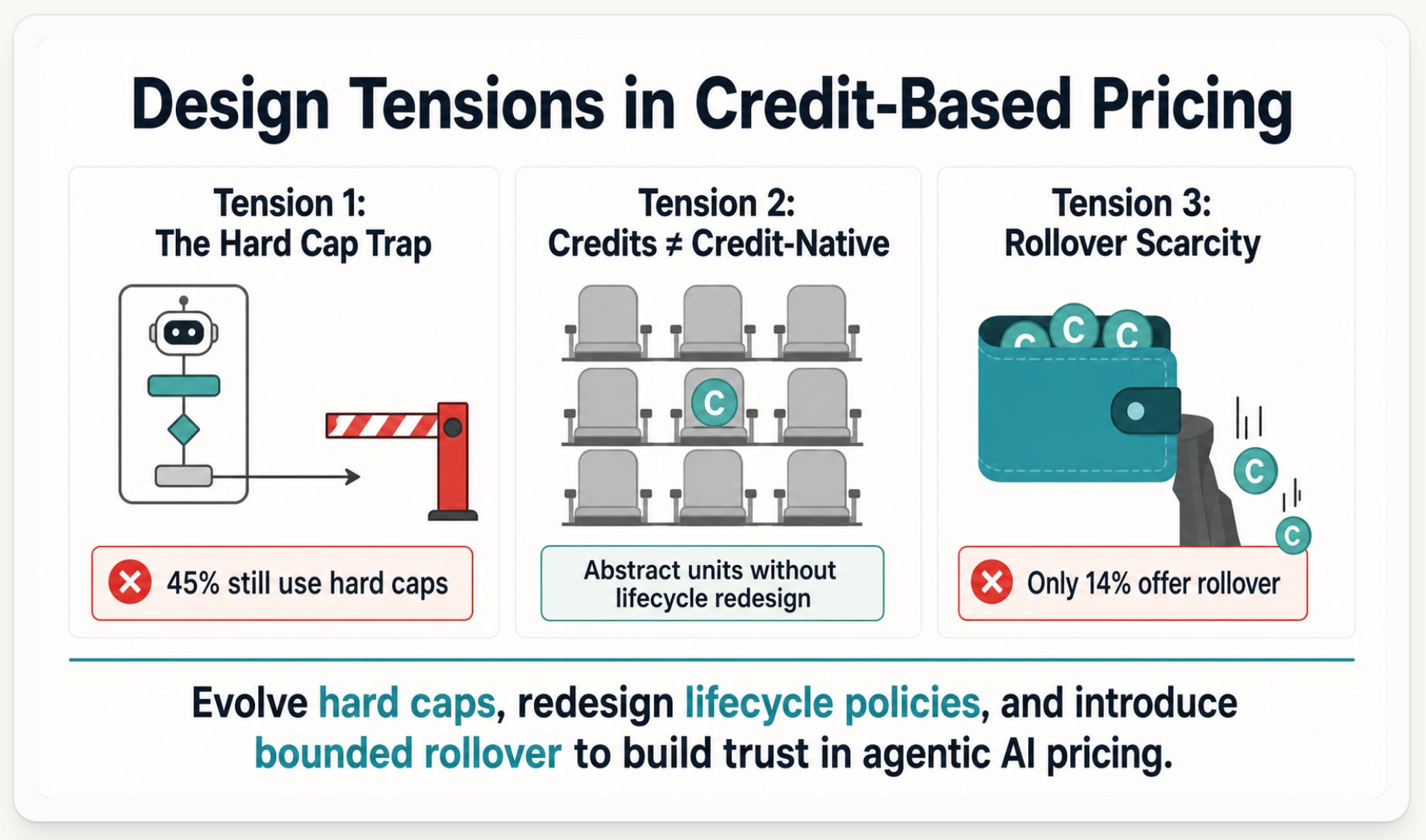
Tension 1: The Hard Cap Trap in AI Products
The most significant design gap in the dataset is the prevalence of Hard Cap overage policies in AI application products. Among AI-specific companies (excluding AI APIs), Hard Cap is used by:
80% of AI Video companies (4/5)
100% of AI Search companies (3/3)
75% of AI Voice companies excluding ElevenLabs (3/4)
50% of AI Productivity companies (3/6)
Hard caps are the weakest overage design from a trust and expansion perspective: “Usage stops at zero credits” creates the worst possible user experience for an agentic workflow that might be mid-execution when credits run out. In the February 2026 Credit based pricing update, there was a 43% hard cap rate in the earlier Tanso 63 dataset. The updated dataset shows this rate has risen slightly to 45%, suggesting the problem is getting worse, not better.
The data reveal why hard caps persist: they cluster with Subscription Revenue (P = 0.74) and Per Seat allocation (P = 0.71). These are not design errors — they are rational choices given the subscription revenue model. The real issue is that companies in the Subscription-Seat archetype need to move to a hybrid model before they can implement softer, more buyer-friendly overage policies.
Tension 2: Abstract Credits Don’t Guarantee Credit-Nativeness
The dataset includes 12 companies using “Credits (Abstract Unit)” as their metric. But credit-native scores among this group vary widely (0 to 5). Jasper uses abstract credits but has a credit-native score of 0: Hard Cap + No Rollover + No PayGo + Per Seat. v0 (Vercel) uses abstract credits but scores 1: Hard Cap + No Rollover + Top-ups only.
This reveals a critical finding: adopting abstract credits as the metric without redesigning the lifecycle core produces a “credits in name only” design. The credits look like credits on the pricing page but behave exactly like seat-based feature quotas. This is precisely the anti-pattern the framework warns against: units defined from cost or tokens “push you into arbitrary lifecycle rules later”. But the converse is also true — units defined as abstract credits but left in a subscription-seat lifecycle framework produce the same poor alignment.
Tension 3: The Rollover Scarcity Problem
Only 10 of 73 companies (14%) allow rollover. Rollover as an important trust mechanism: “Capped rollover: unused credits roll to next period up to a cap” is the recommended default for most credit-based pricing designs. Yet the data show rollover is heavily concentrated in the Consumption-Native archetype (5 companies) and the Credit-Subscription vanguard (3 companies), with almost no rollover in the Subscription-Seat archetype (0 companies).
The reason is structural: subscription revenue models create deferred revenue liabilities when credits roll over, and CFOs resist rollover because it delays revenue recognition. This constraint is real — Fall credits must eventually expire for proper revenue recognition and rollover beyond 12 months causes severe problems with revenue recognition. But the data suggest companies are resolving the tension by defaulting to no rollover rather than designing bounded rollover policies (e.g., roll max 1× the period allowance, expire within 12 months), which the framework identifies as the buyer-friendly middle path.
Patterns Within Categories
AI API (14 companies): The Most Credit-Native Category
The AI API category is the only one where all companies use pooled credit allocation and consumption revenue. The metric is uniformly tokens (input/output) for 11 of 14 companies. Overage is almost universally soft cap with overage charges (12/14 = 86%). This reflects the infrastructure pricing reality: API providers must meter at the token level because that is their cost unit, and soft caps allow the meter to keep running (protecting revenue) while giving customers alerting mechanisms.
The notable exceptions are Anthropic (Claude API), which uniquely offers a “Credit Pool / Prepaid Balance” overage mechanism — the most sophisticated design in the AI API category, scoring 5/5 on credit-nativeness — and Hugging Face, which uses a subscription model rather than consumption, scoring only 2.
Anthropic’s design is worth examining in detail: Consumption Revenue + Token metric + Credit Pool/Prepaid Balance overage + Carry rollover + Top-ups + PayGo + Pooled. This is the only AI API company that has moved from pure token-metered consumption to a prepaid credit wallet architecture — precisely the design pattern the Forth–Mansard framework identifies as the target state for agentic AI pricing. The credit pool/prepaid balance overage mechanism means that customers manage a balance (not a raw token counter), which creates a more legible UX and enables the downstream lifecycle features (rollover, top-ups, pooling) that the framework prescribes.
AI Coding (8 companies): Maximum Design Variance in a Single Category
No other category shows more design diversity. The AI coding category spans the full spectrum from pure seat-subscription (Amazon Q Developer, Sourcegraph Cody, Tabnine, GitHub Copilot) through transitional hybrid (Cursor, v0 Vercel) to fully credit-native (Replit, Windsurf):
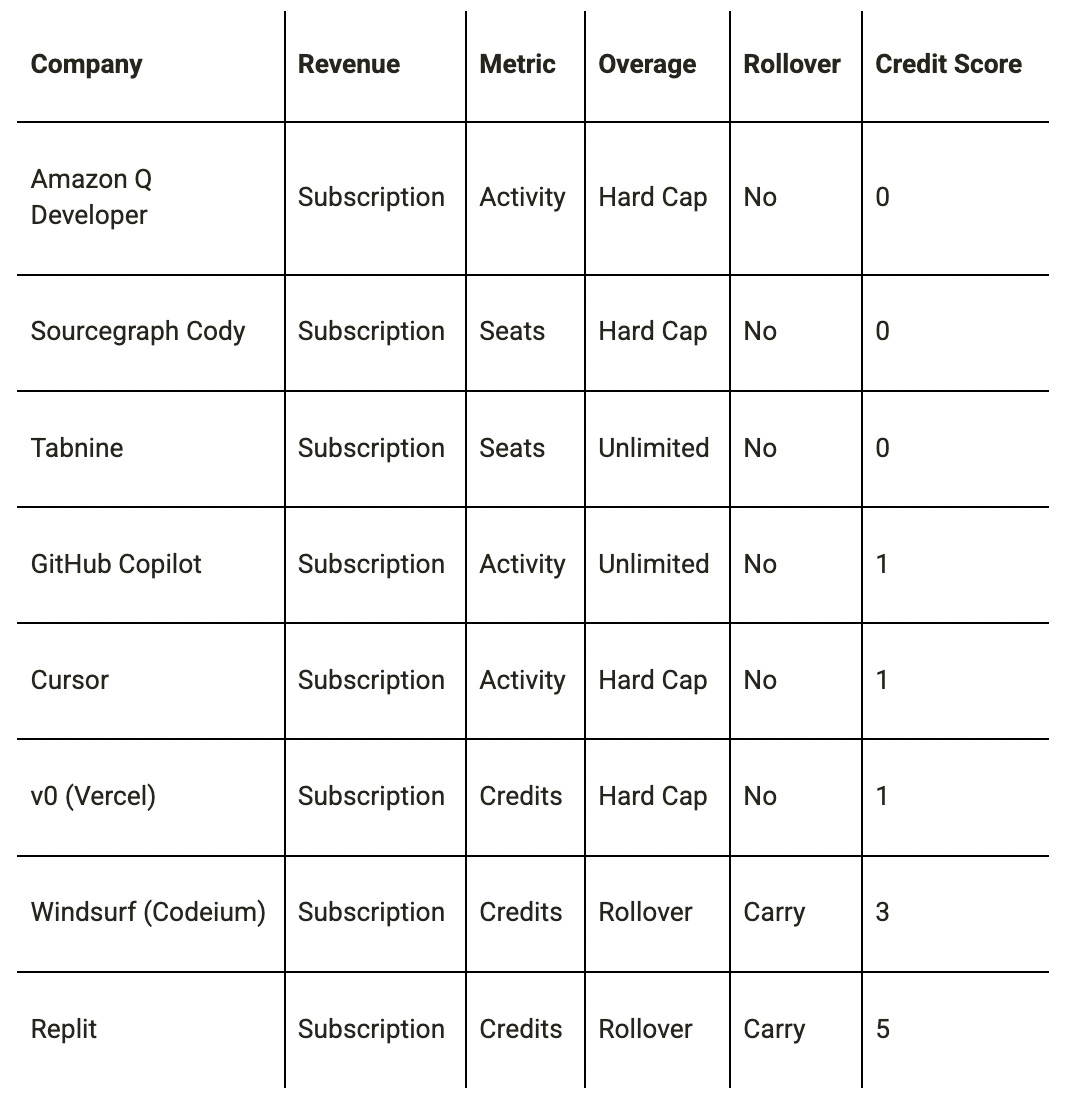
The pattern reveals a competitive divergence that is likely to matter. Replit’s decision to use abstract credits + rollover + top-ups + PayGo + pooling has been explicitly noted as a “vibe coding” best practice. The vibe coding apps (Replit, Windsurf, Lovable, Bolt, v0) are converging on abstract credits with generous rollover as the standard design, while the older AI coding tools (GitHub Copilot, Tabnine, Amazon Q) remain on seat-subscription with unlimited or hard-cap designs. This category is a microcosm of the industry-wide transition from subscription-seat to credit-native design.
AI Video (5 companies): Uniformly Subscription-Seat + Hard Cap
Every AI video company (HeyGen, Pika, Runway, Descript, Synthesia) uses Subscription Revenue + Per Seat + Hard Cap. This is the most homogeneous category in the dataset. The metric varies (credits abstract, media minutes, video minutes), but the lifecycle design is identical: no rollover, 3 of 5 offer top-ups, no PayGo, no pooling.
This uniformity is not surprising: AI video is compute-intensive (consistent with high variable costs that credit-based pricing is designed to absorb) but serves prosumer buyers who want simple, predictable spend. The current designs sacrifice value alignment for simplicity. The strategic risk is that as AI video production costs continue to fall (experience curve), the compute cost pressure that should drive credit-based design will diminish, potentially locking these companies into subscription models that are not optimized for value capture.
AI Voice (5 companies): The ElevenLabs Outlier
The AI Voice category is defined by the contrast between ElevenLabs (score 5) and the other four companies (Fireflies.ai, Murf.ai, Otter.ai, Play.ht — all score 0–1). ElevenLabs is the only voice AI company that has made the full transition to credit-native design: abstract credits, rollover, top-ups, PayGo, and pooling. The others remain on subscription + per-seat + hard cap.
ElevenLabs’ design is likely the result of serving both developer (API) and prosumer (creative) segments — a heterogeneous buyer base that requires the flexibility of credits rather than the rigidity of minute-based subscriptions. This is exactly the condition the Forth framework identifies as “use credit-based pricing if”: multiple use cases with different value profiles and a growing product portfolio.
CRM (4 companies): The Seat-Expansion Defenders
All four CRM companies (Salesforce, HubSpot, Pipedrive, Zoho) use Seat Expansion Revenue + Per Seat + Auto-Upgrade to Next Tier. This is coherent: CRM value is tightly linked to user count (more reps → more records → more value), and auto-upgrade is an elegant expansion mechanism that avoids billing friction. The strategic risk comes from the AI agent layer being added on top: Salesforce Agentforce explicitly introduces credits for agent actions alongside the seat-based core — the emerging hybrid architecture that the Forth framework predicts will become the default for established SaaS vendors.
Data Platform (5 companies): Infrastructure Credit Maturity
Snowflake, Databricks, BigQuery, MongoDB Atlas, and Airtable present an interesting contrast. Airtable is the outlier (Subscription Revenue + Records + Hard Cap + Per Seat, score 0). The four infrastructure platforms are all consumption-based with pooled allocation, and notably, three of them (Snowflake, Databricks, BigQuery) use abstract credits or committed-use discount mechanisms rather than raw token pricing. Snowflake and Databricks score 5/5 — the highest among non-AI-API companies. These platforms demonstrate that mature consumption-based pricing can be credit-native even in non-AI contexts, and their designs serve as reference architectures for AI platform vendors.
Inferences About the Future of Credit-Based Pricing Design
Inference 1: The Metric Abstraction Migration Is Underway but Far From Complete
The data show a clear value chain in metric abstraction levels and their association with credit-native design:
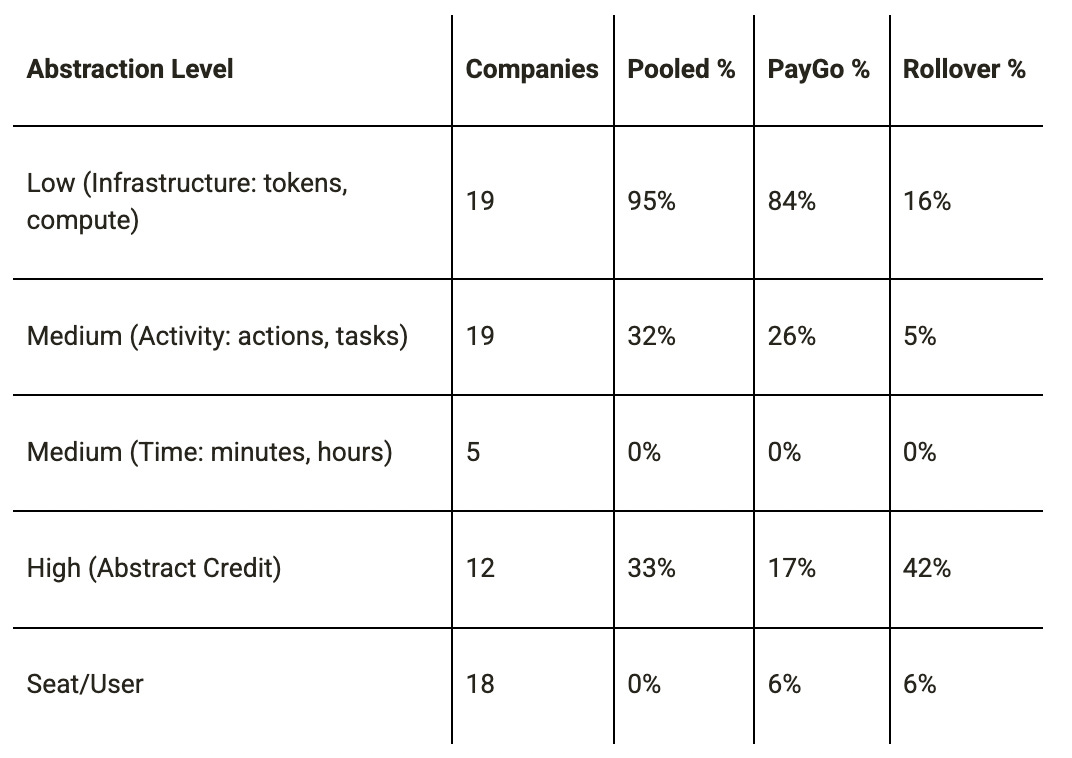
The infrastructure layer (tokens, compute) shows the highest Pay as you Go and pooling rates — but this is driven by the fact that infrastructure pricing is consumption pricing. The more interesting finding is that High (Abstract Credit) companies split almost evenly between credit-native (ElevenLabs, Replit, Snowflake, Databricks, Clay, Windsurf: scores 3–5) and credit-naive (Jasper, v0, Adobe Firefly, Canva, HeyGen, Pika: scores 0–1). Abstract credits are necessary but not sufficient for credit-native design.
The future trajectory is a migration from Low (Infrastructure) metrics toward Activity-based and eventually Abstract Credit metrics as buyer sophistication grows and attribution capabilities improve. The 2026 vibe coding wave is accelerating this migration at the application layer — Replit, Windsurf, Lovable, and their competitors are demonstrating that abstract credits with rollover are commercially viable and buyer-preferred.
Inference 2: The Rollover Gap Will Close — But Slowly
The current rollover rate of 14% is substantially below what the framework predicts should be optimal. Forth identifies capped rollover (carry forward up to 1× the period allowance, expire within 12 months) as the recommended default for credit-based pricing. The data show rollover is clustered in companies with higher credit-native sophistication (Anthropic, OpenAI, ElevenLabs, Replit, Clay, Snowflake, Databricks, BigQuery, Windsurf) and absent in simpler subscription-seat designs.
The structural barrier to rollover adoption is revenue recognition, not design philosophy. Companies with subscription revenue recognise that credit as revenue when it expires — and rollover defers that recognition. As accounting standards for credit-based pricing mature and as companies develop more sophisticated CFO narratives around committed credit pool ARR, rollover will become more common. The prediction: rollover rates in AI application-layer products will roughly double (from ~10% to ~20%) by end of 2027, driven primarily by the Credit-Subscription Hybrid archetype.
Inference 3: The Pooling Convergence
Pooling (Seat Pool = Pooled) is currently at 38% (28/73). The conditional probability data show a near-deterministic rule: Consumption Revenue → Pooled (P = 1.00). All 22 consumption-revenue companies are pooled. Among subscription companies, pooling is present in only 13% (5/39).
The migration toward pooling is therefore directly tied to the migration toward consumption or hybrid revenue models. As more subscription-based AI products move toward hybrid models (subscription base + credit pool), pooling will increase correspondingly. The Clay and ElevenLabs designs — subscription revenue with pooled credits — are the prototype for what this looks like. The prediction: pooling rates will rise from 38% to 50–55% by end of 2027, driven by hybrid subscription-pool architectures in the AI Coding, AI Video, and AI Voice categories.
Inference 4: Soft Cap Will Overtake Hard Cap in AI Application Products
The current hard cap dominance (45% of all companies) is a design artifact of the subscription-seat model, not a buyer preference. The data clearly show that soft cap overage is the dominant mechanism in consumption-revenue products (68%) and is effectively absent in subscription products. As the subscription-seat archetype shrinks and the hybrid credit-subscription archetype grows, the industry-wide overage distribution will shift.
The strategic driver is the Trust Triad (Predictability + Transparency + Fairness): hard caps with no fallback create the worst possible experience when agents are mid-execution. The vibe coding applications, which are currently setting UX standards for credit-based pricing, universally use soft-cap or rollover-credit mechanisms rather than hard stops. The prediction: hard cap rates will decline from 45% to 30–35% by end of 2027 as more AI application products add auto-top-up, soft-cap, or rollover-credit fallbacks to their existing hard cap structures.
Inference 5: The Emerging Governance Gap
One significant design dimension is missing from the Tanso dataset: governance and entitlement visibility. The framework identifies Entitlement & Governance as a “convergence sink” — every upstream design decision flows into dashboards, alerts, consumption simulators, and budget controls. The absence of governance data in the dataset likely reflects that most companies are not yet publishing this level of design detail, which itself may indicate a governance gap.
The companies that have most fully implemented credit-native designs (Anthropic, Snowflake, Databricks) are also the ones most likely to have enterprise-grade governance tooling. The vibe coding companies (Replit, Lovable, Windsurf) are pioneering real-time credit wallet visibility and consumption prediction — behaviors that are “table stakes” for credit-based pricing to work. The prediction: governance tooling (credit balance dashboards, consumption simulators, draw-order transparency) will become a standard feature differentiation point by late 2026, and companies that publish governance capabilities in their pricing pages will have a competitive advantage in enterprise procurement cycles, particularly as AI-mediated buying becomes material. The emerging way to do this is through the JSON schema for value and pricing models provided open source by The Value Project.
Inference 6: The Layer Cake Is Invisible in the Current Data
We have previously introduced a four-layer pricing “layer cake” (Role, Access, Usage, Outcome) as the design palette for agentic pricing. The Tanso dataset shows the usage layer (consumption metrics, overage) and access layer (subscription architecture) reasonably well, but the Role Layer (agent role pricing vs. human labor cost) and Outcome Layer (performance-tied pricing) are not apparent at all.
This is not a data collection failure — it reflects the state of the market in mid-2026. Most agents in 2026 operate in Phase 1 (simple usage or role+access pricing), with a small number in Phase 2 (credits + quantitative EVE). Phase 3 (outcome-layered, dynamic pricing) is largely aspirational. The dataset would need two additional columns — Role-Based Pricing (yes/no) and Outcome-Based Component (yes/no) — to capture the full strategic picture. Adding these in the next Tanso update would significantly increase the dataset’s analytical power.
Inference 7: Agent-to-Agent Commerce Will Stress Current Credit Architectures
The emerging agent-to-agent commerce paradigm introduces requirements that current credit architectures are not designed for. When a buyer agent is orchestrating multiple sub-agent purchases on behalf of an enterprise, the current per-product credit wallet model creates fragmentation: the buyer agent must manage separate credit pools across Anthropic, OpenAI, ElevenLabs, Replit, and any other vendors it uses. The emergence of cross-vendor credit wallet infrastructure — possibly through MCP (Model Context Protocol) or similar standards — will require a redesign of the Transfer and Trading dimensions which are currently almost universally absent from the designs in the Tanso dataset.
The strategic implication: companies that invest now in making their credit systems interoperable (well-documented APIs, machine-readable pricing schemas, standardized credit denomination logic) will have structural advantages in the agent economy’s procurement layer. The Tanso dataset does not currently capture interoperability features, which is another dimension worth adding.
Design Pattern Summary Table
Conclusions and Design Recommendations
The Tanso dataset confirms that credit-based pricing design is bifurcating: a small, sophisticated cluster of consumption-revenue and credit-subscription hybrid companies (30–35% of the dataset) has designed coherent credit systems with high lifecycle richness, while the majority of AI application products remain on subscription-seat models with hard caps and minimal lifecycle flexibility.
The five most actionable design recommendations from this analysis, grounded in both the Forth–Mansard framework and the empirical patterns:
Move from Hard Cap to Auto-Top-Up + Alert as the default overage mechanism. The Hard Cap + No Pay as you Go combination creates the worst trust outcome for agentic workflows. Auto-top-up with configurable thresholds is the buyer-friendly alternative that preserves spend control while eliminating mid-execution stops.
Don’t adopt abstract credits without redesigning the lifecycle core. The data show that 5 of 12 abstract-credit companies have credit-native scores of 0–1. Adopting abstract credits as the metric without redesigning overage, rollover, and pooling produces credits in name only — the most common and most costly implementation error visible in this dataset.
Design rollover as a tiered entitlement, not a binary choice. No rollover for free tiers; capped rollover (1× period allowance) for paid tiers; more generous rollover for higher tiers. The current 14% rollover rate is far below the framework’s recommended default and reflects an accounting-driven conservatism that can be resolved with proper CFO communication about committed credit pool ARR.
Add pooling before adding rollover. The data show that 80% of rollover companies are also pooled. Pooling first creates the shared credit inventory that makes rollover meaningful at an organizational level rather than an individual one. The sequence matters: implement pool-level architecture before adding rollover, to prevent individual credit overhang.
Prepare for the governance layer now. The dataset does not capture governance capabilities, but the framework is clear that Entitlement & Governance (C14) is the convergence point for all upstream decisions. Real-time dashboards, consumption simulators, and FEFO draw-order transparency are emerging as enterprise procurement requirements. Companies that can demonstrate governance maturity will command a trust premium, particularly in regulated industries.