
What do Anthropic's recent pricing moves imply for the long-term pricing of frontier models
Unit prices that rise with consumption and innovation at the edge

The success of Claude Code and its new frontier model Mythos have propelled Anthropic to the head of the generative AI industry. Anthropic has a decisive lead over OpenAI in terms of model performance, revenue growth (Q2 2026 revenue was $10.6 billion, more than double Q1 revenue) and company value at $965 billion has passed OpenAI at $852 billion. Anthropic even had an operating profit in Q2. What Anthropic decides will shape generative AI and the agents and applications built on it.
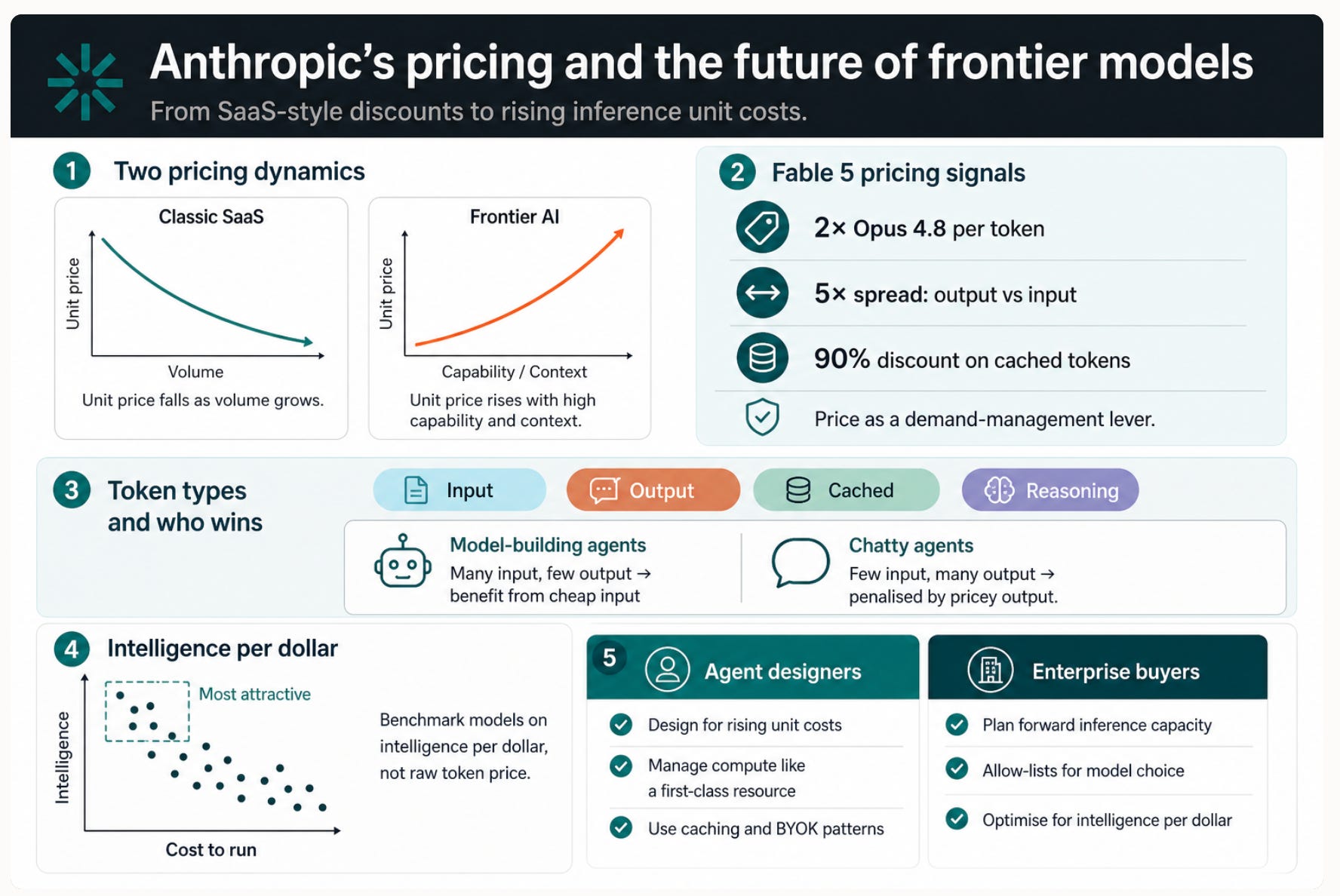
The release of Fable 5, as the general release of the Mythos model is named, came with some interesting pricing moves. Pricing is used to shape behaviour and to signal future intention, so it worthwhile trying to read the tea leaves here.
Key things to note about Fable 5 pricing
Fable 5 costs 2X Opus 4.8 while maintaining the 5X differential between input and output tokens.
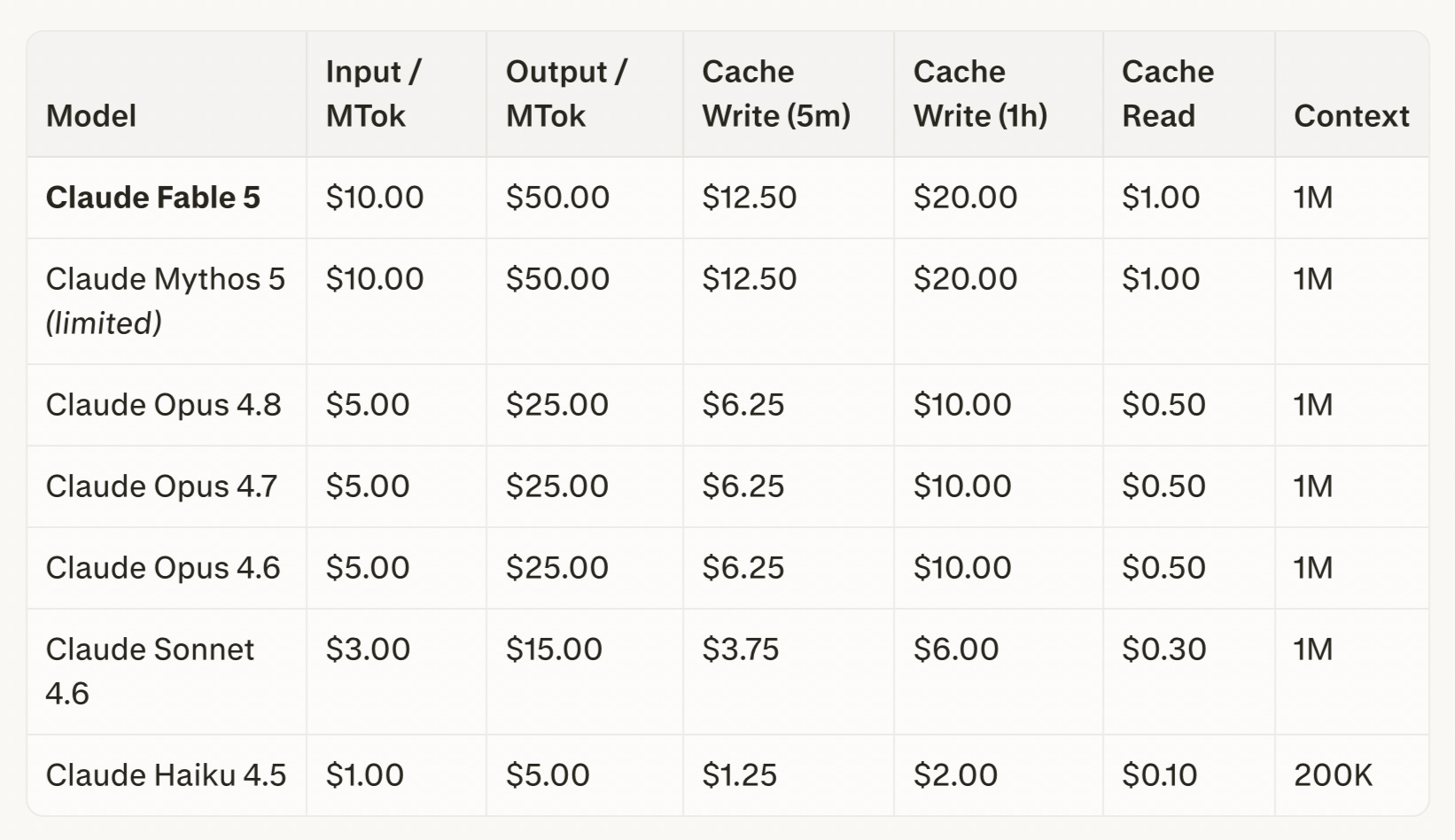
Note that there is also a 90% discount on cached tokens. Input tokens that have already been processed once and are being reused on subsequent calls are billed at a cheaper “cache read” rate instead of the normal input rate. Other vendors have some version of this but Anthropic has the most clarity and the steepest discount.
All seat based plans are going to have to buy tokens to access Fable 5, it can be accessed through some plans like (and not just the API) but the price for Fable 5 is not included in the monthly price. Anthropic has said that this is a temporary expedient that will go away once the inference supply-demand relationship normalises, but when might that be?
Comparing pricing of the top frontier models
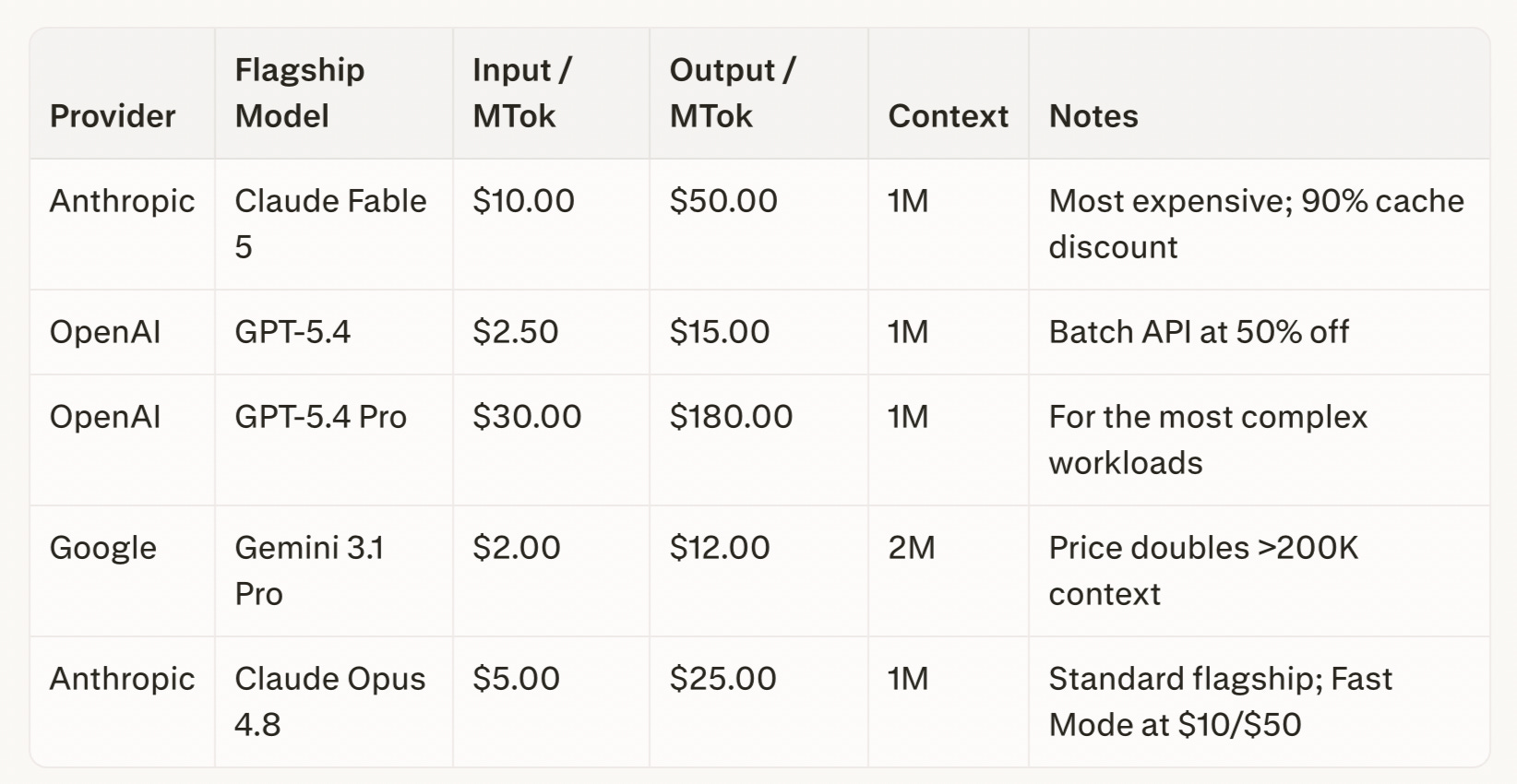
Note that the most expensive model is still OpenAI GPT-5.4 Pro. The models have different intended uses though. GPT-5.4 Pro is meant for agentic workflows and tool use. Each prompt is likely to be much smaller. Fable will be used for top-end coding and reasoning. Prompts could get quite large, though the use of cached tokens will help keep costs down.
Note also that Google has a step function where price per token doubles when context is larger than 200K (context is the number of tokens in a prompt, the larger the context the better the one-shot learning).
There are details in token pricing beyond the price per token that impact how much people end up paying.
Intelligence per dollar as a value metric
It is tempting to compare token prices directly but this is not that meaningful.
Different models generate different quality of output (and this can be measured)
The same task can consume different numbers of tokens
The number of input tokens to get the same output can differ
The number of output tokens in which the output is expressed can differ
The number of intermediate tokens and how they are priced can wildly differ (cached tokens is an example)
It is a best practice to have a rubric to measure the quality of AI outcomes, and this can be used to estimate the value of the output. valueIQ’s agents are stuffed with rubrics to ensure that models and processes are continually improving.
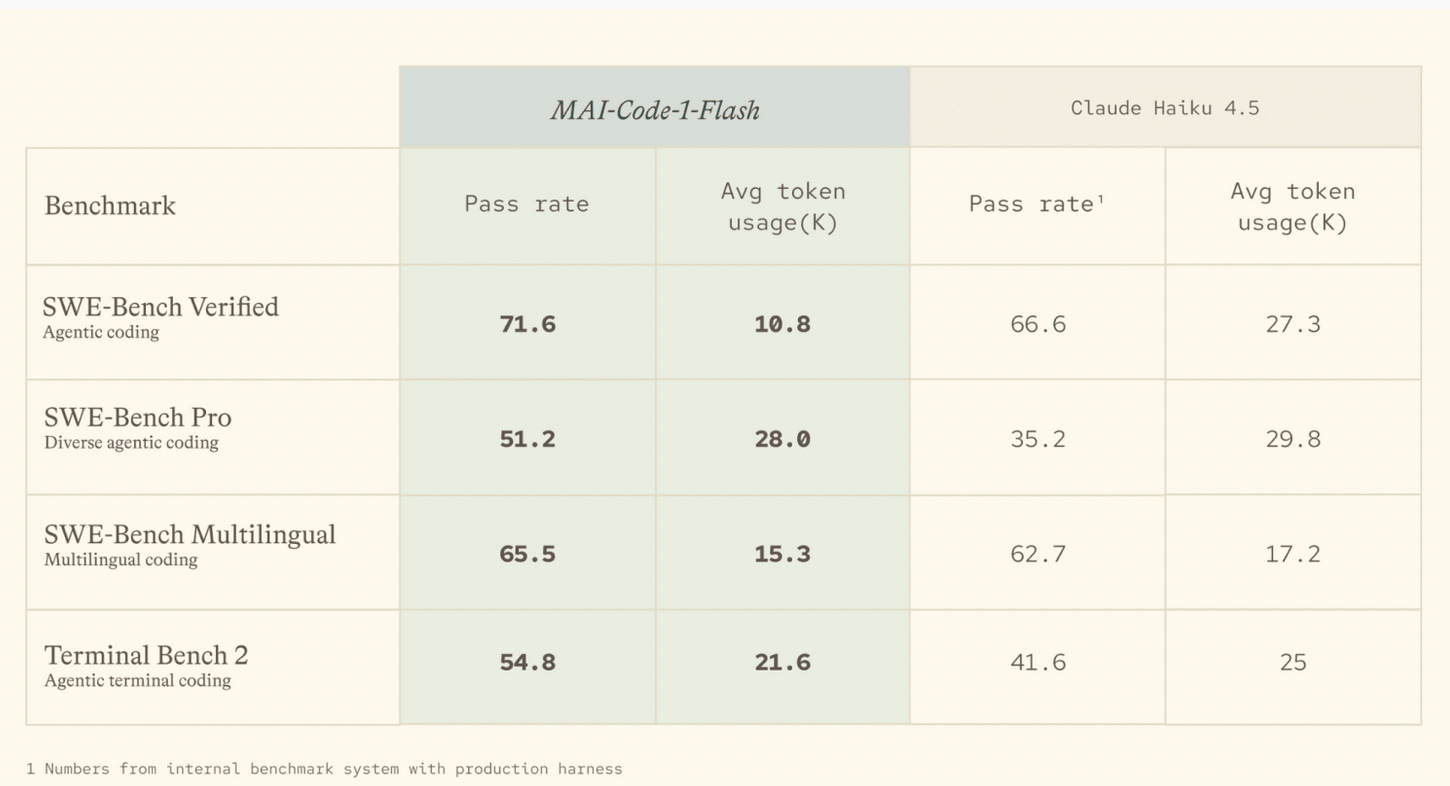
An example of this is Intelligence per Dollar. Tom Tunguz suggested this metric after seeing the above table in a Microsoft Model Release Card. See “Introducing MAI-Code-1-Flash — Microsoft announces a new coding model with average token usage on the release card.”
Benchmarks are measured on two different dimensions, the overall performance & the cost to achieve that intelligence. From this, with the token costs, one can derive the intelligence per dollar.
This metric can then be used to compare models and be used to decide which model to use for a specific task. Not every task needs to use the most powerful model.
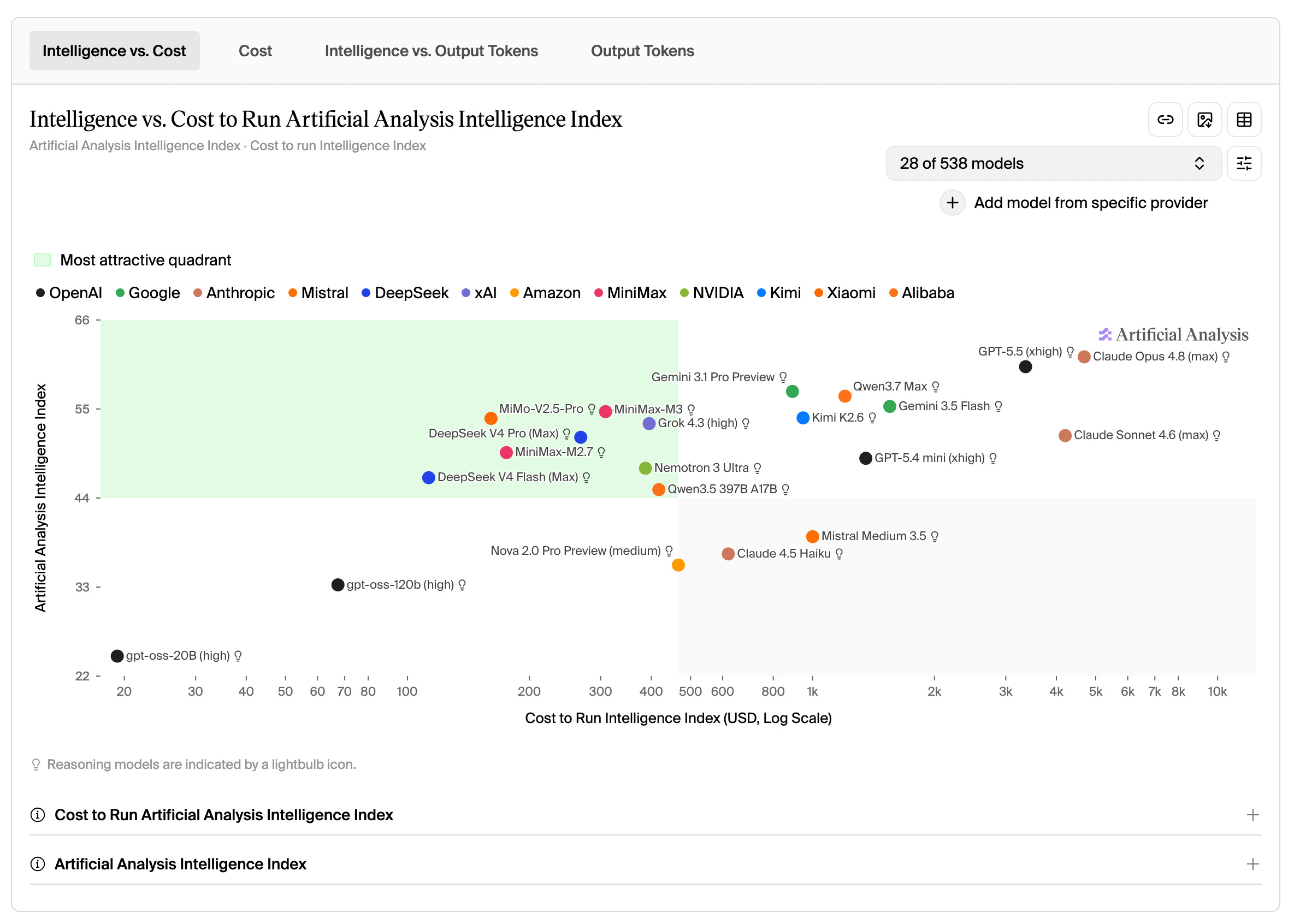
A good place to track this is Artificial Analysis, a site that gathers and validates many key AI metrics. They publish a distribution of Intelligence to Cost to Run. This is basically Tunguz’s intelligence per dollar. It does not yet include Fable 5 or Mythos 5. One would generally be using models in the top half of this graph, unless cost was the prime consideration, in which case one would want to be as far to the left as possible (and still get the results one wants).
Anthropic is using price to manage demand
One of the key messages around Mythos/Fable pricing is that supply challenges are driving pricing decisions. This is not something people are used to in SaaS, where supply has been elastic for the past two decades (in large part thanks to AWS and Azure). The operating assumption is that unit price will decline with scale. When supply is constrained this is not the case and price can increase with consumption. The more inference you consume the higher the unit costs can be. That is a very different dynamic.
Anthropic has said credit pricing for Fable is a temporary expedient, but that is what governments said when they introduced income tax, and in any case it does not look like the supply crunch on AI infrastructure is going to go away anytime soon. AI inference will be priced like electricity. There will be caps on usage, discounts for doing inference in off hours, large inference consumers will contract access in advance, and so on.
This approach to pricing will cascade down onto the pricing of agents. Cost plus pricing may be a poor pricing model, but that does not mean that pricing can ignore costs and if unit costs increase with volume pricing will start to evolve in very different ways.
Agents will be optimised to manage compute (inference cost optimisation will emerge as an important category over the next year) and many agents will try to transfer compute costs to the buyer (bring your own key BYOK and choose your own model). If unit price goes up with use buyers will change their behaviours and agent design will have to respond.
Procurement will become as concerned with managing forward capacity as it is with optimising current prices. They will begin specifying which models can be used and extracting price concessions when cheaper and open source models are in play.
None of us has internalised a world in which unit price goes up with consumption but that is the world we are moving towards.
Implications of the Price Difference Between Input and Output Pricing
Different prices for different types of token has been normalised and will become more common. Four types of token are used in pricing today:
Input tokens
Output tokens
Cached tokens
Reasoning tokens (this is currently hidden but expect it to come back for high end models)
Are there other types of token that could be priced? I am sure the pricing teams at frontier model vendors are asking this.
Different use cases can have wildly different token consumption patterns.
An agent that generates a model (like valueIQ.ai value model generation) will have far more input tokes than output tokens. Agents of this type benefit from the current pattern where input tokens are cheaper than output tokens.
An agent that is long form discursive, verbose, like many agents that are glorified chatbots, are penalised by the current low-input high-output price pattern.
Some smart developer of foundation models will soon differentiate by having a model with the opposite pattern, high-input low-output price, and will target agents that benefit from this.
A lot happens between input and output, more and more all the time. Frontier model vendors will be looking at how to better monetise this. Cached tokens, reasoning tokens, shared tokens, inferred tokens … there are many possibilities.
Innovation in frontier model pricing is likely to begin at the edges, the dominant vendors are growing fast and are focussed on crude levers. They don’t want or need the distraction of complex pricing models. But specialist and edge models have opportunities to differentiate by designing pricing that fits different token consumption models. I will be looking for innovation on places like Hugging Face (which currently has more than 2.9 million models and more than 1 million datasets).
Conclusion
Conclusion: Design for rising unit costs
Anthropic is telling us that frontier model pricing will not follow the classic SaaS curve where unit prices fall with volume; for the next several years, unit prices are likely to rise with consumption, especially at the high‑end of capability and context. This is a fundamental break with the assumptions most of us have been using in our AI business cases.
Three shifts matter for anyone building agents and applications on top of these models. First, intelligence per dollar becomes the operative value metric, not raw token price, and you need your own rubrics and benchmarking harnesses rather than relying on vendor marketing. Second, token heterogeneity is here to stay: input, output, cached, and (soon again) reasoning tokens will each have different prices and different economics by use case. Third, inference supply is constrained and being managed with pricing, so forward capacity planning and contracted access start to look more like electricity and less like traditional cloud SaaS.
So what should you do now?
Map your top 5–10 agent workflows to their token consumption patterns and explicitly model how costs change when unit prices rise with usage.
Adopt intelligence‑per‑dollar (or a close cousin) as a core KPI in your model selection and experimentation process, and track it over time rather than making one‑off choices.
Redesign agents to manage compute as a first‑class resource: aggressive caching, smarter context construction, and BYOK patterns that give enterprise buyers control over model choice and price–performance trade‑offs.
Engage procurement early around forward inference capacity and model allow‑lists, including when and how cheaper or open‑source models can substitute for frontier models.
If you are a specialist or edge model vendor, treat token‑type pricing as a design surface and look for segments where an unconventional input/output/cached mix can create a structural advantage.
We are moving into a world where innovation in pricing will be as important as innovation in models. The teams that internalise rising unit costs, design agents around compute constraints, and treat pricing as a lever for behaviour and value capture will be the ones that build durable advantage in the next generation of AI products.